



针对Linux内核中double fetch漏洞的研究
作者:王鹏飞 国防科技大学计算机学院网络安全实验室
近年来,并行程序随着多核CPU硬件的普及而被越来越广泛的使用,特别是在操作系统、实时系统、以及计算密集型系统中,并行程序极大地发挥了并发处理的优势。然而并行程序中存在的并发错误(concurrency bug)因为线程调度引入了不确定性而呈现难检测、难复现、难修复的特点。数据竞争(data race)是并行程序中普遍存在的情况,当多个线程同时访问某一共享内存地址且其中至少一个是写操作,而这些访问操作在没有必要的同步措施保护时就会引发数据竞争。数据竞争极易引发并发错误,包括死锁(deadlock),原子性违例(atomicity violation),顺序违例(order violation)等。当并发错误可以被攻击者利用时,就形成了并发漏洞。历史上由竞争引发的并发错误曾多次造成重大安全事故,如著名的Therac-25医疗事故曾造成多人死伤,2003年的北美大停电曾造成数十亿美元的经济损失等。
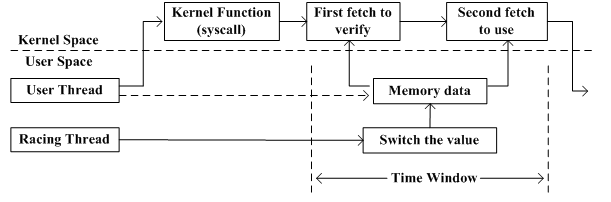
图1 Double Fetch原理
系统中的竞争不只会发生在线程间,还可能发生在内核与用户线程间,Serna[1]将这一特殊的竞争称之为double fetch。如图1所示,用户通常会通过调用内核函数完成特定功能,当内核函数两次从同一用户内存地址读取同一数据时,通常第一次读取用来验证数据或建立联系,第二次则用来使用该数据。与此同时,用户空间并发运行的恶意线程可以在两次内核读取操作之间,利用竞争条件对该数据进行篡改,从而造成内核使用数据的不一致。Double fetch漏洞可造成包括缓冲区溢出、信息泄露、空指针引用等后果,最终造成内核崩溃或者恶意提权。
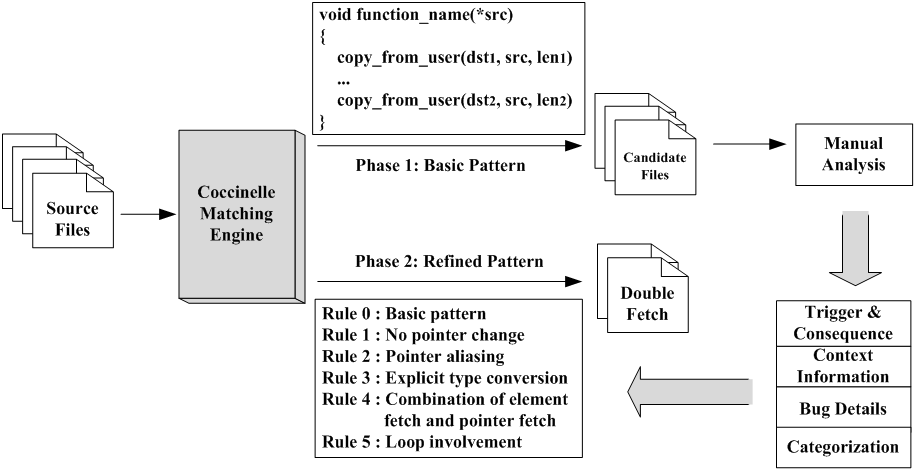
图2 方法框架
针对Linux内核中的double fetch问题,我们基于Coccinelle引擎,提出了一种静态模式匹配的检测方法,该方法能够检测完整内核(包括所有驱动程序)代码而不必依赖特定硬件。如图2所示,我们的方法分两个阶段,首先根据double fetch定义从源代码中进行模糊匹配,即匹配多次调用copy_from_user()或get_user()等拷贝函数从用户同一地址读取数据的内核函数。然后人工分析这些匹配到的函数,基于此,我们总结了用户数据是如何传递到内核中的以及在内核中是如何被使用的,并且归纳了3个容易造成double fetch的典型使用场景:size checking, type selection, shallow copy。此外我们还收集了double fetch问题在代码实现层面的细节。在第二阶段中,基于上一步中收集到的double fetch特征和细节,我们进行精准模式匹配的double fetch检测。我们将所提方法应用到Linux,Android,FreeBSD后,共发掘未知double fetch漏洞6个,如表1所示。
表1 发掘的double fetch漏洞
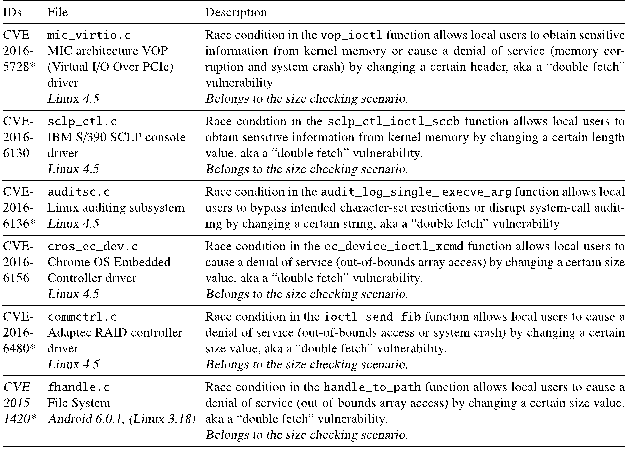

图3 CVE-2016-6480
在这里,我们简要介绍一个属于size checking场景的double fetch漏洞(CVE-2016-6480)。该漏洞位于Linux 4.5中Adaptec RAID控制器驱动文件commctrl.c中。如图3所示,函数ioctl_send_fib() 两次通过copy_from_user()拷贝指针arg指向的用户空间数据(分别为81和116行)。第一次只拷贝了消息头,并用消息头中的数据来计算缓冲区大小(第90行),检查数据的有效性(第93行),并根据计算结果来分配相应的缓冲区(第101行)。第二次拷贝(第116行)则根据第一次获取的消息长度将完整消息拷贝进分配好的缓冲区中。注意此时指向内核缓冲区的指针变量kifb被再一次使用了(第101行)。在第二次拷贝之后,新拷贝的消息头中的许多变量被再次使用(而它们可能已经被篡改),例如第121和129行的kfib->header.Command。尤其是消息头中的长度变量也被再一次使用(第130行),从而引发了一个double fetch漏洞,因为恶意用户线程可能在两次拷贝之间篡改消息头中的长度变量kfib->header.size,使得第二次读取并使用的值远大于第一次分配的缓冲区大小,从而造成buffer over-access。
结合以上研究,我们还提出了5条针对double fetch问题的预防策略,并基于其中一条实现了一个工具自动为已发现的double fetch漏洞打补丁。除此之外,我们还有如下有趣发现:
- Double fetch是个普遍性的问题,Windows,Linux,Android,FreeBSD等操作系统都存在此类问题,有的漏洞已经存在10年以上(CVE-2016-6480)。
- 大部分double fetch情况并不会造成double fetch漏洞,因为两次读取的数据不一定会被交叉使用。但是良性的double fetch情况容易在代码更新时由于交叉使用两次读取的数据而转化成有害的漏洞(CVE-2016-5728)。
- 内核中有些数据使用情况会不可避免的引发double fetch,我们归纳了3个主要场景:size checking, type selection, shallow copy,并提出了预防策略。
- 大部分的double fetch存在于驱动程序中(63%)。
- Size checking场景最容易引发double fetch漏洞。
目前所发掘漏洞已得到Linux内核开发团队的确认、修复并集成到主干分支。所提检测方法及发现已经被Coccinelle团队和Linux内核开发团队采用并集成到内核补丁审计中。相关论文“How Double-Fetch Situations turn into Double-Fetch Vulnerabilities: A Study of Double Fetches in the Linux Kernel”已发表在系统安全领域著名会议USENIX Security 2017,详细信息请参阅论文。
参考文献:
1.Serna, F. J. MS08-061: the case of the kernel mode doublefetch,2008. https://blogs.technet.microsoft.com/srd/2008/10/14/ms08-061-the-case-of-the-kernel-mode-double-fetch/.
作者简介:
王鹏飞,博士生,国防科学技术大学计算机学院网络安全实验室,导师卢凯研究员。研究领域为系统安全,并行程序分析等。2015-2016年在英国伦敦大学学院CREST研究中心访学,与Jens Krinke合作研究double fetch问题,撰写论文“How Double-Fetch Situations turn into Double-Fetch Vulnerabilities: A Study of Double Fetches in the Linux Kernel”发表在系统安全领域著名会议USENIX Security 2017。




