



InForSec学术年会将于2019年1月18~19日在清华大学举办,今年的主题是“网络安全四大国际会议论文分享及产学对话”。诚挚邀请您出席此次学术年会,共同探讨国际网络安全领域最新的研究成果和发展趋势,分享学者们研究过程中的灵感、经验和体会。来自产业界百度、360、阿里等知名企业的代表将介绍他们的研究热点和需求,商讨学术和产业合作的机会。
我们还开设了“中国好导师&网安企业大牛”的对话环节,共同探讨如何做出高水平的研究成果、如何寻找产业合作机会、如何培养研究型的人才。我们热切期待您的参与,分享您对学术社区未来发展的建议。
主题:网络安全四大国际会议论文分享及产学对话
时间:2019年1月18日~19日(周五、六)
地点:清华大学FIT楼二层多功能厅
主办:网络安全研究国际学术论坛(InForSec)
协办:清华大学网络科学与网络空间研究院
复旦大学软件学院系统软件与安全实验室
百度安全
360企业安全集团
中国科学院软件研究所可信计算与信息保障实验室
中国科学院信息工程研究所信息安全国家重点实验室
中国科学院计算技术研究所计算机体系结构国家重点实验室
北京大学计算机科学技术研究所
中国科学院大学国家计算机网络入侵防范中心
浙江大学网络空间安全研究中心
视频直播:www.inforsec.org/live
会议议程
演讲嘉宾及议题介绍
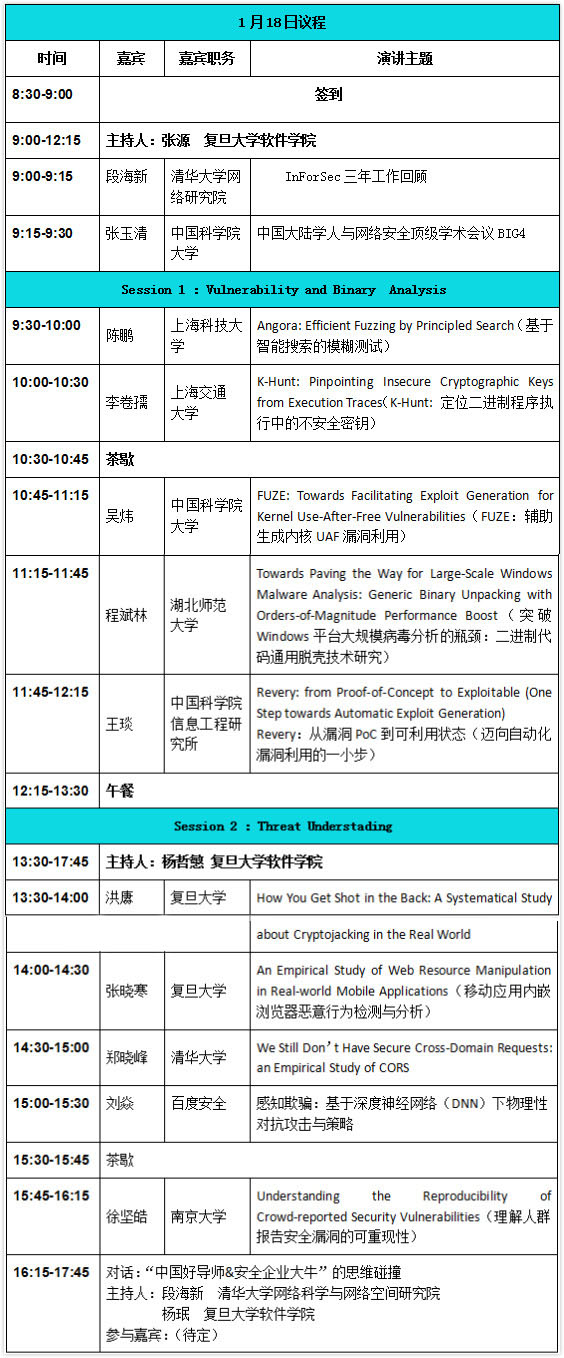
Session 1 :Vulnerability and Binary Analysis
1、演讲人:陈鹏 上海科技大学
演讲主题:Angora: Efficient Fuzzing by Principled Search(基于智能搜索的模糊测试)
内容摘要:
如何去更好地生成输入来触发更多的程序状态是基于覆盖率的模糊测试方法的一个关键挑战。结合符号执行的模糊测试方法能够产生高质量的输入,但是它们的运行速度很慢;使用随机修改来产生输入的模糊测试方法能运行得很快, 但无法产生高质量的输入。 我们提出了Angora, 一个新的基于修改的模糊测试工具。 Angora的主要目标是在不使用符号执行的前提下去解决路径约束来提高代码覆盖率。为了更高效地解决路径约束, 我们提出了四个关键技术:可适应的字节级别的污点跟踪,上下文敏感的分支计数,基于梯度下降搜索的约束求解方法,输入长度的智能探索。根据这些技术,Angora在LAVA数据集和真实程序中比其他模糊测试工具能够找到更多的漏洞和覆盖更多的代码块。
2、演讲人:李卷孺 上海交通大学
演讲主题:K-Hunt: Pinpointing Insecure Cryptographic Keys from Execution Traces
(K-Hunt: 定位二进制程序执行中的不安全密钥)
内容摘要:密钥(crypto keys)是现代密码学中至关重要的秘密信息,也是密码系统中需要保密的唯一元素。理解密钥在密码软件中的使用、发现不安全的密钥使用特例,对于密码学系统的安全审计而言极为关键。为了帮助分析人员更好地定位密钥、分析密钥在软件中(特别是二进制代码中)的使用,我们设计并实现了K-Hunt,一款基于二进制代码插桩分析的密钥自动化安全分析系统。K-Hunt关注密钥使用的本质特征从而定位密钥区域(key buffers),继而追踪密钥数据的整个生命周期(生成、使用和销毁),从中发现不安全的密钥使用问题。K-Hunt的设计哲学保证它不需要特定的密码算法知识就能发现不安全密钥使用——通过对10款典型的密码学算法库和15个密码学软件的分析表明,K-Hunt不仅广谱地定位了所使用的对称、非对称密码算法中的密钥信息,还在这25个测试用例中发现其中22个均存在密钥的不安全使用,其中包括知名的密码算法库(Libsodium, Nettle, TomCrypt, WolfSSL)
3、演讲人:吴炜 中国科学院大学
演讲主题:FUZE: Towards Facilitating Exploit Generation for Kernel Use-After-Free Vulnerabilities(FUZE:辅助生成内核UAF漏洞利用)
内容摘要:软件提供商常常根据漏洞可利用性来安排漏洞修复优先级。但是确定漏洞可利用性通常耗费大量时间和人工分析。为解决这个问题,我们可以采用漏洞利用自动生成技术(AEG)。但在实际中已有的技术并不能应用于解决内核释放后重用漏洞(UAF)。这主要是因为UAF漏洞利用和内核执行环境的复杂性。在本文中我们提出了FUZE—一个为内核UAF利用提供便利的框架。具体来说,FUZE使用内核模糊测试以及符号执行来发现、分析和评估对于漏洞利用有帮助的系统调用。为了展示FUZE的实用性,我们在64位Linux操作系统上实现了FUZE原型系统。通过15个Linux内核UAF漏洞组成的测试集,我们展示了FUZE不仅可以辅助内核UAF漏洞利用生成,还可以辅助一些内核缓解机制的绕过。
4、演讲人:程斌林 湖北师范大学
演讲主题:Towards Paving the Way for Large-Scale Windows Malware Analysis: Generic Binary Unpacking with Orders-of-Magnitude Performance Boost(突破Windows平台大规模病毒分析的瓶颈:二进制代码通用脱壳技术研究)
内容摘要:在过去的二十年里,海量的加壳病毒一直是Windows反病毒领域里一个巨大挑战。我们的研究从一个新的角度重新审视了长期存在的二进制通用脱壳问题:加壳程序通常会混淆标准的Windows API调用, 然后在原始代码恢复执行之前重建 IAT。在加过壳的恶意软件执行过程中, 如果正在调用的API是通过查找已重建的 IAT进行寻址的,则表明原始代码已经被还原。基于此,我们设计一种高效的脱壳方法, 称为 “BinUnpack”。与以前的通用脱壳方法相比, BinUnpack 没有繁琐的指令级的内存访问监控, 只使用了API级的访问监控。同时,为绕过一系列的抗脱壳方法,我们设计了一种新的API监控方式:内核级 DLL 劫持。实验结果表明,BinUnpack 的脱壳成功率明显优于现有的方法并且具有1-3个数量级的性能提升。
5、演讲人:王琰 中国科学院信息工程研究所
演讲主题:Revery: from Proof-of-Concept to Exploitable (One Step towards Automatic Exploit Generation)(Revery:从漏洞PoC到可利用状态(迈向自动化漏洞利用的一小步))
内容摘要:漏洞利用是漏洞研究中最具挑战性的问题,在实践中主要依靠安全人员的经验和高超技巧完成。学术界对此问题进行了一些探索尝试,出现了诸如AEG、Mayhem等方案。美国国防部DARPA于2014年发起了为期2年的Cyber Grand Challenge,吸引众多团队参与并开发设计了7个自动化攻防原型系统。然而,现有的自动化漏洞利用方案仍存在极大局限性(例如不支持堆相关漏洞利用),离实用还有较大距离。
在本议题中,演讲人将介绍其最新研究成果Revery,支持将堆漏洞PoC样本自动转化为能够触发可利用状态的PoC样本,可以辅助安全人员生成利用样本,在简单防御情形下可以自动化生成漏洞利用样本。我们在二进制分析平台Angr的基础上,开发出一个Revery原型系统,并使用了19个CTF漏洞利用题目进行了实验。实验结果表明,对于造成堆错误、内存读错误、甚至不造成崩溃的PoC,Revery可生成劫持控制流或触发可利用状态的漏洞利用代码。
在本议题中,演讲人还将分享自动化漏洞利用中有待解决的其他难题,探讨自动化利用的未来方向。
Session 2 :Threat Understading
6、演讲人:洪赓 复旦大学
演讲主题:How You Get Shot in the Back: A Systematical Study about Cryptojacking in the Real World
内容摘要:随着17年比特币等数字加密货币价格的全线上涨,比特币、莱特币、门罗币等加密货币逐渐走入人们的视野之中。利益驱使着黑客们把目光从正规渠道挖矿转向盗取他人计算资源挖矿。近来,互联网上有用户、媒体反映其在访问一些网站的时,电脑会变得十分卡顿,甚至完全卡死。经研究发现,该情况是由于一些不法分子在web服务器上部署恶意脚本进行挖矿造成的。在网页上挖矿的危害是巨大的,轻则会使用户在毫无防备的情况下电脑变慢、卡顿、直至死机,重则还有可能由于长时间的CPU高负荷运转导致用户的硬件受损。
web端挖矿形势愈演愈烈,在用户看到的“网页变慢、系统卡顿”的背后,是整个web端挖矿在作祟。目前,恶意挖矿行为也从一开始最原始的暴力挖矿逐渐向更复杂形态发展。目前业界对于web端挖矿防御大部分是基于黑名单的。但是根据作者的研究结果指出黑名单只能防范不到一半的恶意挖矿网站。为了提高挖矿行为的检出率,作者针对网页挖矿的行为特点,提出了基于动态监控程序执行的调用栈的恶意挖矿行为检测技术,切实有效的提高了挖矿行为的检出率。作者还从大规模检测的结果出发,针对整个web端挖矿的生态系统进行了系统性的研究。
7、演讲人:张晓寒 复旦大学
演讲主题:An Empirical Study of Web Resource Manipulation in Real-world Mobile Applications(移动应用内嵌浏览器恶意行为检测与分析)
内容摘要:目前,内嵌式浏览器(WebView)被广泛应用在移动应用中,用来集成各种各样的Web服务。这种方式可以简化开发过程并保持在不同平台的可移植性,但是也给被集成的Web服务带来了数据泄露的风险。我们系统化地分析了这种这种新型威胁的技术原理,并提出了同安全主体原则来区分恶意行为和正常行为。我们综合利用程序静态分析、自然语言处理以及搜索引擎技术,开发了自动化检测工具,并在Android和iOS官方应用商城中检测出了数十款具有恶意行为的应用。这些恶意应用的总安装量已达上亿次,对用户造成了严重的安全危害。
8、演讲人:郑晓峰 清华大学
演讲主题:We Still Don’t Have Secure Cross-Domain Requests: an Empirical Study of CORS
内容摘要:出于安全的目的,Web浏览器的同源策略(Same Origin Policy)限制了跨域的网络资源访问。然而,开发者由于业务的需要许多时候必须访问跨域的资源。跨域资源共享CORS(Cross-Origin Resource Sharing)是目前解决跨域资源访问的最为正规的方案,也得到了所有主流浏览器、许多热门Web网站的支持。该报告发现CORS的设计、实现与现实网络中的配置都存在大量的安全问题。该报告对现实世界的CORS所做的大规模实证研究,发现攻击者可以利用CORS安全漏洞可以绕过防火墙攻击内网二进制服务、利用之前不可利用的CSRF漏洞和获取任意网站敏感的Cookie信息等。此外,还对Alex 排名5万的域名下的9千多万网站进行了大规模的测量,发现支持CORS的网站中有27.5%的网站存在配置安全风险,其中包括mail.ru、fedex.com、washingtonpost.com以及国内知名的网站和搜索引擎。最后,对CORS的设计和部署提出了改进建议以降低风险,并介绍开发的一个Web服务器CORS配置的漏洞扫描器。
9、演讲人:刘焱 百度安全
演讲主题:感知欺骗:基于深度神经网络(DNN)下物理性对抗攻击与策略
内容摘要:报告展现了让物体在深度学习系统的“眼”中凭空消失,在AI时代重现了大卫•科波菲尔的经典魔法。针对深度学习模型漏洞进行物理攻击可行性研究,这个领域的研究有着广泛的用途,在自动驾驶领域、智能安防领域、物品自动鉴定领域都有重要的实际意义。百度安全的这个研究也启示了工业界及学术界需要更加迫切的研究人工智能感知系统的安全问题,共同探索与建设安全的AI时代。
10、演讲人:徐坚皓 南京大学
演讲主题:Understanding the Reproducibility of Crowd-reported Security Vulnerabilities(理解人群报告安全漏洞的可重现性)
内容摘要:现今的软件系统越来越依赖“人群的力量”来识别新的安全漏洞。 然而,人群报告(crowd-reported)安全漏洞的可重现性尚未被充分了解。 作者对大范围的真实世界安全漏洞(总共368个)进行了首次实证分析, 以量化其可重现性。 根据一个精心控制的工作流程,作者组织了一个专门的安全分析师小组来进行复现实验。 在花费了3600个工时(man-hour)后,作者得到了漏洞报告中信息缺失的普遍性和漏洞的低可重现性的大量证据。 调查发现,由于信息不完整,仅依赖主流的安全论坛的单个漏洞报告通常很难成功复现漏洞。 通过广泛的众包信息收集,安全分析师可以提高复现成功率,但仍然面临着解决不可复现案例的关键挑战。 作者发现,在互联网规模的众包失效的情况下,安全专业人员严重依赖手动调试和推测性猜测来推断缺失的信息。 本报告表明,不仅改进安全论坛收集漏洞报告的方式是必要的,还需要自动化机制来收集漏洞报告中常见的缺失信息。
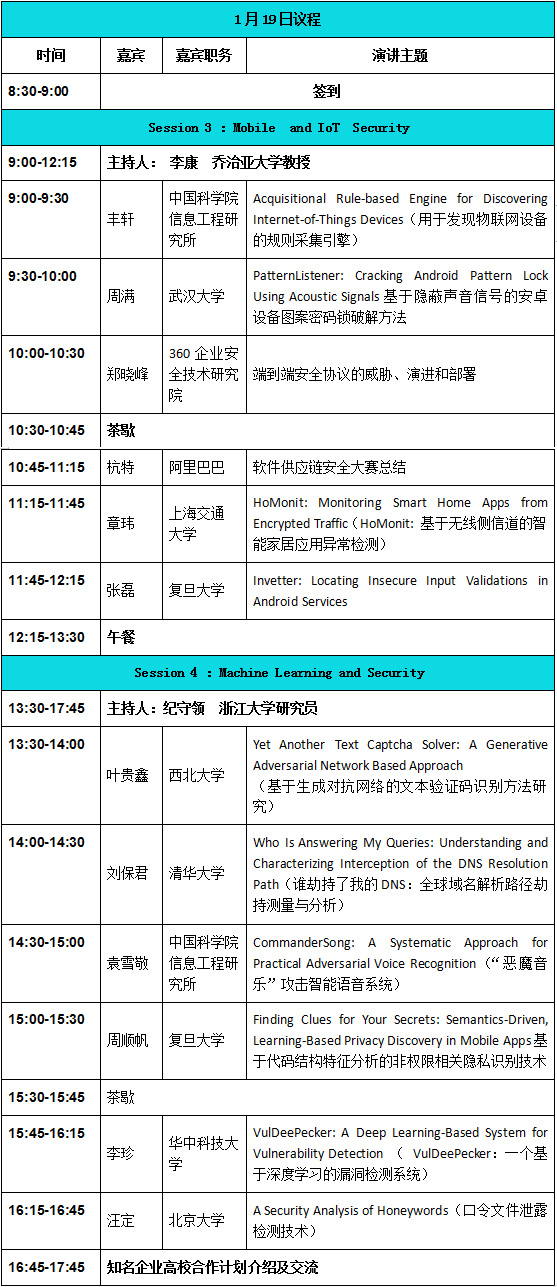
1月19日
Session 3 :Mobile and IoT Security
11、演讲人:丰轩 中国科学院信息工程研究所
演讲主题:Acquisitional Rule-based Engine for Discovering Internet-of-Things Devices(用于发现物联网设备的规则采集引擎)
内容摘要:物联网技术的高速发展,给网络空间中物联网设备的管理和安全审计引入了巨大的技术挑战。这些物联网设备通常来自不同的设备类型,供应商,具有不同的产品型号。物联网设备发现和标识是了解,监控和保护物联网设备的先决条件。但是,现有手动标识物联网设备的方法无法满足大规模设备发现的需求,现有基于机器学习的设备分类需要大量带标签的数据。因此,在物联网中自动发现和标识的设备仍然是一个亟需解决的问题。
本文提出了一个规则获取引擎(ARE),可以在没有任何训练数据的情况下,自动生成发现和标识物联网设备的规则。 ARE利用来自物联网设备应用层的响应数据和相关网站中的产品描述,来自动构建用于标识设备的规则。通过从设备的应用层响应信息中提取相关特征字段,在搜索引擎中搜索该关键字爬取对应页面。结合自然语言处理技术从描述页面中提取设备标识,并基于关联算法生成标识物联网设备的规则。最后我们进行验证实验和三个基于ARE的应用来验证其有效性。
12、演讲人:周满 武汉大学
演讲主题:PatternListener: Cracking Android Pattern Lock Using Acoustic Signals基于隐蔽声音信号的安卓设备图案密码锁破解方法
内容摘要:通过隐蔽声音信号破解安卓设备图案密码锁。针对已有的移动设备图案密码锁攻击方法鲁棒性和隐蔽性不强,可扩展性差的缺点,我们设计和开发了一种新颖的基于声学原理的图案密码锁破解方法。图案密码锁被广泛用于身份认证从而保护移动设备(例如智能手机)上的数据安全与用户隐私。近年来研究者们提出了多种图案密码锁攻击方法,然而这些攻击方法对受害者所处环境具有高度敏感性,并且无法扩展。我们发现手指在移动设备屏幕上的滑动可以通过附近的声音信号进行追踪,因此设计和开发了一种新颖的基于声学原理的图案密码锁攻击方法。我们的方案不需要攻击者物理接近目标设备,对环境干扰也不敏感,能够同时推断大量用户的图案密码锁,因此具备很强的鲁棒性和可扩展性。相关研究成果《PatternListener: Cracking Android Pattern Lock Using Acoustic Signals》,已经被通信与计算机安全国际会议ACM CCS 2018录用。
13、演讲人:郑晓峰 360企业安全技术研究院
演讲主题:端到端安全协议的威胁、演进和部署
内容摘要:在互联网短短几十年的历史上,各种新技术、新产品的发展日新月异。只要涉及互联网接入或互联互通,必然涉及到协议标准的制定、实现和更新,安全协议和安全通信产品更是如此。本报告将回顾部分网络安全协议的历史发展过程,总结他们发展成功的经验与失败的教训、分析工业实现部署的现状与问题,希望对安全协议的制定、实现与部署提供一些参考。
14、演讲人:章玮 上海交大
演讲主题:HoMonit: Monitoring Smart Home Apps from Encrypted Traffic(HoMonit: 基于无线侧信道的智能家居应用异常检测)
内容摘要:智能家居,作为一个由物联网衍生的新兴概念,可智能连接各类智能传感器和设备,促进家用电器、照明、加热冷却系统以及安防系统的自动化。三星 SmartThings 作为一个开放的智能家居平台,在同类平台中占据领先优势。我们的研究围绕三星 SmartThings 展开。过往相关研究揭露了 SmartThings 设计上的若干安全缺陷。这些缺陷将允许智能家居应用(又称作 SmartApp)非法获取到未被授予的权限,且可能引发 SmartThings 平台上的事件欺骗攻击。为解决该问题,我们利用侧信道推测技术,设计并实现了一个可以通过分析加密无线流量来监控应用行为的系统,称为 HoMonit。通过对比从应用的源代码或 UI 交互界面提取的预期行为和从加密流量中推测的实际行为,HoMonit 系统可以实现对应用异常行为的检测。为了评估 HoMonit 系统的有效性,我们分析了 181 个官方提供的应用,并对基于此开发的 60 个恶意应用进行了评估检测。这些应用对智能设备存在越权访问或事件欺骗攻击的行为。实验结果表明,HoMonit 系统可以有效验证智能家居应用的工作逻辑,并且在检测应用异常行为方面具有较高的准确度。
15、演讲人:张磊 复旦大学
演讲主题:Invetter: Locating Insecure Input Validations in Android Services
内容摘要:Android系统整合了越来越多的系统服务,其中不乏地理位置、电话、短信等各种敏感服务及资源。为了防止恶意软件利用这些系统服务非法获取敏感的系统资源,Android系统实现了一套基于访问控制的机制去保护这些服务。虽然,已经有很多工作研究了这些访问控制中的漏洞问题,但是,他们都集中于研究那些基于权限验证的访问控制,还有一大类基于输入验证的访问控制,却被疏忽了。而本文就是针对那些尚未被研究过的存在于Android系统服务中的输入验证。虽然Android系统服务中包含了很多输入验证,但是我们发现,识别他们仍然有很多困难,因为他们分布非常离散,而且缺少结构化特征,也没有文档说明。为了解决这些困难,我们实现了一个叫做Invetter的工具。该工具通过利用机器学习和静态分析去识别敏感的输入验证,再结合一些安全规则进行漏洞检测。最终,通过对8个Android系统镜像的扫描,我们发现了约20个漏洞。
Session 4 :Machine Learning and Security
16、演讲人:叶贵鑫 西北大学
演讲主题:Yet Another Text Captcha Solver: A Generative Adversarial Network Based Approach
(基于生成对抗网络的文本验证码识别方法研究)
内容摘要:验证码被广泛应用于网站的登录、注册等环节,用来进行身份验证以防止计算机自动程序暴力破解、刷票或垃圾评论等。其中文本验证码由于密码空间大、交互方式简单等特点目前仍被大多数主流网站使用。为了增大计算机程序对文本验证码自动识别的难度,一方面,当前文本验证码普遍使用了复杂混淆背景、字符扭曲、旋转和粘连等安全特征,导致基于分割-识别的方法失效。另一当面,有些网站也采用了防爬机制以限制验证码被恶意收集和自动爬取,并且频繁更换验证码方案,导致基于深度学习模型的识别方法由于不能及时获取大量训练数据而失效。本文提出了一种基于生成式对抗网络(GAN)的文本验证码解算器。该解算器通过合成大量与真实网站风格相似的验证码,然后利用合成验证码训练CNN识别模型,最后使用少量真实数据优化CNN识别模型来实现。我们使用33个主流网站(其中包括11个Alexa全球排名前50的网站)中所使用的验证码进行了评估,实验结果表明,我们的方法不仅由于其他识别方法,而且可以破解其他方法不能破解的验证码方案。
17、演讲人:刘保君 清华大学
演讲主题:Who Is Answering My Queries: Understanding and Characterizing Interception of the DNS Resolution Path(谁劫持了我的DNS:全球域名解析路径劫持测量与分析)
内容摘要:公共域名解析服务器由于其良好的安全性与稳定性被一些互联网用户所信任。 我们发现,这层信任关系会轻易地被域名解析路径劫持所破坏。网络中的旁路设备伪装成公共域名解析服务器的IP地址,进而劫持用户的域名解析流量,并转发到第三方域名服务器。通过全球范围内大规模的网络测量,我们发现全球两百余个自治域内存在这种现象;而在中国,近三成谷歌公共DNS的域名解析流量被劫持。这一现象给用户带来了多种安全隐患。这项研究工作发表于国际网络安全顶级会议USENIX Security (’18)(CCF A 类会议)。
18、演讲人:袁雪敬 中国科学院信息工程研究所
演讲主题:CommanderSong: A Systematic Approach for Practical Adversarial Voice Recognition(“恶魔音乐”攻击智能语音系统)
内容摘要:智能语音控制成为当前机器接受人类命令的常用方式,传统攻击需要入侵到汽车或者机器人系统中。利用声音信号欺骗人工智能系统可以避免物理接触设备,但是如何克服播放设备电子噪声以及环境噪声的影响,规模化地攻击智能语音识别系统是实现实际物理攻击的难题。
本文旨在研究智能语音应用的潜在威胁和防御机制,为人工智能算法测试与修复提供思路。主要基于语音识别原理,挖掘深度学习算法漏洞,自动化地将语音命令嵌入到任意歌曲中生成对抗样本,这种被称为CommanderSong的“恶魔音乐”可以在人们无法觉察的情况下大范围地实际物理攻击智能语音识别系统。此外,这种攻击还可以通过网络或者收音机信号进行广泛传播,进而在人们日常生活中误导商业化应用产品(如科大讯飞)。
19、演讲人:周顺帆 复旦大学
演讲主题:Finding Clues for Your Secrets: Semantics-Driven, Learning-Based Privacy Discovery in Mobile Apps基于代码结构特征分析的非权限相关隐私识别技术
内容摘要:移动应用功能的日益丰富往往伴随着不断演化的新型安全隐患,其中隐私泄露的有效检测也随之面临更加严峻的挑战。当前移动应用具有与多来源第三方服务深度交互、与云端服务器紧密通信的特点,大量移动应用往往会以比传统方式更加复杂的形式来访问并使用用户高度敏感的隐私数据。具体而言,由于大量应用越来越多包含与个人账户相关敏感信息,且同时很大一部分敏感信息来自于远程云端服务器,这样的敏感通信更加复杂且隐蔽。
为了发现移动应用中存在的各类隐私泄露隐患,首先需要确定的是应用中的敏感信息来源。如已有工作通关相关的系统API来确定敏感信息源(如IMEI,电话号码,GPS位置等),或通过界面相关资源结合语义信息进行用户输入隐私数据的识别。然而,对于来自远程服务器端的敏感数据,其通常往往通过不具有任何特点的通用网络接口(如HTTP请求)直接进行传输通信,更难以有效检测其中的隐私泄露隐患。由于这类数据与传统应用中有系统权限模型管控的敏感数据相对应,且不具有固定特征,在本文研究中将其定义为非权限相关隐私数据。
本文研究提出一种全新基于代码结构特征分析的非权限相关隐私数据识别技术。通过利用程序代码中的结构特征,使用基于自然语言处理技术与机器学习模型相结合的全新标识方式来对隐私数据进行有效标识。在此基础上,本文设计并实现了名为ClueFinder的非权限相关隐私数据识别系统,适用于大规模自动化识别移动应用中的非权限相关隐私数据。本方法的核心出发点在于,移动应用代码中的字符串常量中往往包含丰富的语义信息来表明相关数据内容。与此同时,移动应用代码片段自身所具有的多项结构特征,能够辅助用于识别其所关联的特定数据结构是否包含潜在的用户隐私,甚至能够直接辅助不依赖于传统信息流分析来判断所关联的隐私片段是否存在隐私泄露的情况。该方法不仅能够有效识别传统隐私数据无法覆盖的来自于远程云端服务器的用户个人隐私数据,同时还能从另一角度很好地覆盖传统的各类隐私,使得识别结果能够作为新的信息流分析的起始点,有效辅助后续的信息流分析。
与此同时,利用该技术所提供的非权限相关隐私数据识别能力,本文针对移动应用中涉及到第三方类库的隐私数据使用情况进行了深入分析研究。通过使用基于该技术所识别的隐私数据,对接近45万款流行应用进行了大规模的隐私泄露风险评估,从而从新的角度探究应用商城中的隐私数据如何被各类第三方服务插件使用。该项研究能够有效评估移动应用第三方插件中的隐私泄露风险状况,同时为后续针对性的隐私保护方案提供有效指导参考。
20、演讲人:李珍 华中科技大学
演讲主题:VulDeePecker: A Deep Learning-Based System for Vulnerability Detection ( VulDeePecker:一个基于深度学习的漏洞检测系统)
内容摘要:软件漏洞的自动检测是一个重要的研究问题。现有的漏洞静态分析方法存在两个问题:第一,依赖人类专家定义漏洞特征;第二,漏报较高。理想的漏洞检测系统是同时满足低误报和低漏报,当二者无法同时满足时,更好的方法是强调降低漏报,只要误报在可接受的范围内。针对上述问题,我们首次将深度学习技术引入到面向源代码的漏洞检测领域,提出了在切片级别基于深度学习的漏洞检测系统VulDeePecker。基于双向长短期记忆网络模型自动学习生成漏洞模式,在不需人类专家定义特征的前提下,自动检测目标程序是否含有漏洞,并给出漏洞代码的位置。实验结果表明,VulDeePecker在可接受的误报前提下,比其他方法具有更低的漏报;在3个目标软件中检测到4个在National Vulnerability Database中未公布的漏洞,这些漏洞在相应软件的后续版本中进行了默默修补。
21、演讲人:汪定 北京大学
演讲主题:A Security Analysis of Honeywords(口令文件泄露检测技术)
内容摘要:近一两年来,大批的知名网站(如Yahoo, Dropbox, Weebly, Quora, 163,德勤)发生了用户口令文件泄露事件。更为严重的是,这些泄露往往发生了多年后才被网站发现,才提醒用户更新口令,然而为时已晚。比如,Yahoo在2013年泄露了30亿用户口令和各类个人身份信息,在2017年10月才发现,因此事件导致Verizon对Yahoo的收购价格降低了10亿美金。
Honeywords 技术是检测口令文件泄露的一种十分有前景的技术,由图灵奖得主 Rivest 和 Juels在ACM CCS’13 上首次提出。本研究发现,他们给出的4个主要 honeywords 生成方法均存在严重安全缺陷,且此类启发式方法无法简单修补;进一步提出一个honeywords 攻击理论体系,成功解决“给定攻击能力,攻击者如何进行最优攻击”这一公开问题;反过来,攻击者的最优攻击方法可被用来设计最优 honeywords 生成方法,成功摆脱启发式设计。本研究将使honeywords生成方法的设计和评估从艺术走向科学,为及时检测口令文件泄露提供理论和方法支撑。




