



作者:郭文博( 宾夕法尼亚州立大学),Jun Xu(Stevens Institute of Technology)
简介
近年来,深度神经网络在网络安全应用上展现了强大的潜力。目前为止,我们已经看到了深度神经网络在恶意软件聚类,逆向工程,以及网络入侵检测中取得了很好的效果。尽管如此,由于神经网络的不透明特性,安全从业人员对于他们的使用依旧十分慎重。具体而言,深度神经网络可能由大量的数据集训练而成并且存在上百万个神经元。 这种高度的复杂性使得我们很难理解神经网络的某些决策,从而导致了诸如无法信任神经网络以及无法有效判断神经网络的错误等问题。
为了增强神经网络的透明性,研究者们已经开始探索新的方法来解读神经网络的分类结果。然而,这些方法难以用于解释在安全领域的深度学习。第一方面,已有的方法主要是用于解释深度学习在图像分析领域的应用,被解释的模型通常是Convolutional Neural Networks (CNN)。然而,在安全应用方面,比如逆向工程和恶意软件分析领域,通常我们使用具有更高扩展性,更强特征关联性的模型,比如Recurrent Neural Networks (RNN) 或者Multilayer Perceptron Model (MLP)。到目前为止,没有解释模型可以被用于RNN。第二方面,现有的方法通常有较低的解释精度。对于拥有模糊边界的应用而言,比如图像识别,相对较低的解释精度是可以接受的。但是对于安全应用,比如二进制分析而言,即使对于一个字节的解释偏差也会导致严重的误解或者错误。
在这个工作中,我们尝试构建一种新型的,具有高解释精度的模型用于安全应用。我们的方法属于黑盒方法,并且通过特殊的设计来解决以上的挑战。给定一个输入样本x以及一个分类器,比如RNN,我们的方法尝试去发现那些对于归类x起重要作用的关键特征。技术上来说,我们对于x附近区域的决策边界生成局部拟合。为了提高拟合的精确度,我们的方法不假设分类器的决策边界是线性的,我们也不假设不同的特征之间是独立的。相反,我们借用混合回归模型来近似非线性的局部决策边界,同时我们通过fused lasso来加强解释精度。这样一种设计一方面提供了足够的灵活性来优化对于非线性决策边界的拟合,另外一方面fused lasso 可以很好的抓住不同特征之间的依赖性。为了更加方便的阐述,我们将我们的方法称为LEMNA (Local Explanation Method using Nonlinear Approximation) [1]。
为了验证我们解释模型的有效性,我们利用LEMNA来解释深度学习在安全方向的两个应用:PDF malware的聚类以及在二进制代码中寻找函数边界。在这两个应用中,聚类器分别是通过10000 个PDF文件以及2200个二进制程序来训练的。他们都达到了98.6%以上的精度。我们将LEMNA用来解释他们的聚类结果并且开发了一系列的指标来验证我们解释的正确性。这些指标表明在这些分类器以及应用中,LEMNA显著的优于已有的解释方法。在准确度评估之外,我们还展示了安全分析员和机器学习开发者将如何从我们的解释结果中受益。
我们的工作主要带来以下几个贡献:
- 我们设计并且开发了LEMNA, 一种专门用于解释安全应用中的深度学习的方法。我们的方法结合混合回归模型以及fused lasso,提供高精度的解释结果。
- 我们在两个不同的安全应用上评测了LEMNA,包括PDF恶意软件聚类,以及二进制代码的函数边界确定。我们提出了一系列的指标来评估我们解释结果的精确度。我们的实验显示LEMNA显著的优于现有的解释方法。
- 我们论证了我们的解释模型的实际应用。不论是二进制代码分析,还是恶意软件检测,LEMNA都阐释了为什么聚类器会做出正确的或者错误的决定。我们同时还开发了一种简单的方法来自动将我们得到的启发变成修正模型错误的可行方案。

相关背景
接下来,在具体介绍的技术细节之前,我们先介绍一些相关的背景知识。首先,我们会对可解释机器学习给出一个定义,并且讨论相关的解释技术。然后,我们会对利用深度学习的关键安全应用进行简介。最后,我们会详细描述为什么已有的解释技术不适用于这些安全应用。
问题定义 可解释机器学习尝试对于分类的结果给出可理解的解释。具体而言,给定一个输入 x 以及一个分类器 C,这个分类器在测试时会给 x 一个标签 y。解释技术的目标是阐释为什么x 被分类成y。通常的做法是标定使得分类器给出决策的关键性特征。如果这些被选择的特征是可以理解的,那么我们就认为这些特征给出了一个解释。Figure 1展示了基于图像分类以及情感分析的例子。我们可以通过选择特征来解释这些分类器的决策(比如,突出关键像素和关键字)。在这个工作中,我们主要聚焦于解释安全应用中的深度学习。技术上来说,我们的工作可以归类为黑盒解释方法。接下来,我们具体讲述黑盒解释的工作原理。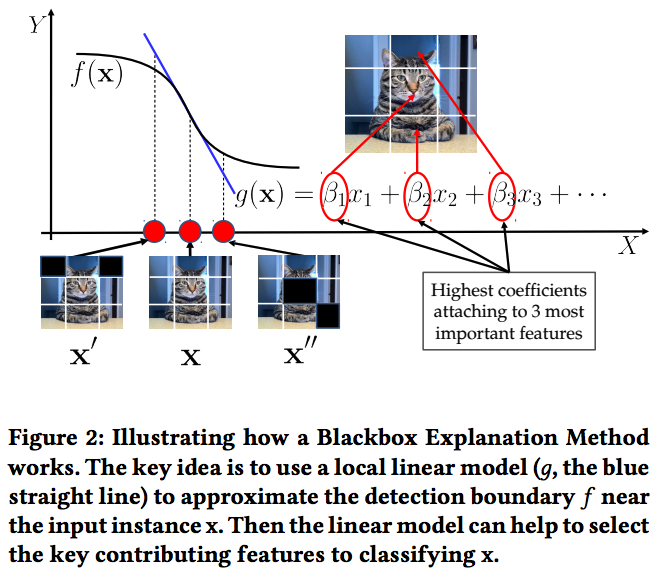
黑盒解释方法不需要理解诸如网络结构和参数等分类器的内部结构。取而代之的是,他们将分类器视为黑盒子然后通过对于输入输出的观察来进行分析(即模型推断方法)。这个类别里面最有代表性的工作是 LIME [2]。给定一个输入 x (比如一个图片), LIME系统性的扰动x来从x的邻近特征区域里面获取一系列新的人工样本 (比如 Figure 2中的x ′ 和x ′′ )。我们将这些人工样本放到目标分类器 f(x) 里面去获取相应的样本, 然后我们用线性回归模型 g(x) 来拟合这些数据。这个 g(x) 试图去模拟f(x)在特征空间中位于输入样本附近区域的决策。LIME假设在输入样本附近的局部决策区间是线性的,因此用线性回归模型来局部代表 f(x) 的决策是合理的。由于线性回归是可自解释的,因此LIME可以基于回归系数来标定重要的特征。
解释安全应用 虽然深度学习在安全应用上面已经展现了巨大的潜能,但是我们却极度缺乏对应的解释模型。结果是,透明度的缺乏降低了可信度。首先,安全从业者可能不能信任深度学习模型如果他们不知道关键的决策是怎么做出的。第二,如果安全从业者不能诊断分类器的错误(比如,由于畸形的数据引入的错误),那么这些错误可能在后面的实用中被放大了。接下来,我们介绍两个成功使用深度学习的关键性安全应用。然后我们讨论为什么已有的解释方法在这些安全应用中不适用。
在这个工作中,我们关注两类安全应用:二进制代码逆向和恶意软件聚类。二进制代码分析中的深度学习应用包括寻找函数边界,确定函数类型,以及相似代码定位。比如说,Shin [4] 他们用一个双向的RNN来改进函数边界寻找,实现了几乎完美的结果。对于恶意软件分类,现有的工作主要通过使用MLP模型来进行大规模恶意样本聚类。
利用现有的解释方法来解释以上的深度学习应用有极大的挑战。在 Table 1中,我们总结了一个可行方法的必要特征,以及为什么现有的解释技术不适用:
- 大部分的解释方法是为用于图片聚类的CNN而设计的。但是,我们关注的安全应用主要使用的是RNN或者MLP。由于模型上的不匹配,现有的解释方法是不适用的。诸如LIME的黑盒模型不能很好的支持RNN。
- 像LIME这类的黑盒方法假设不同的特征是不相关的,但是RNN跟这个假设是冲突的,因为RNN明确地会捕捉序列数据中的特征依赖。
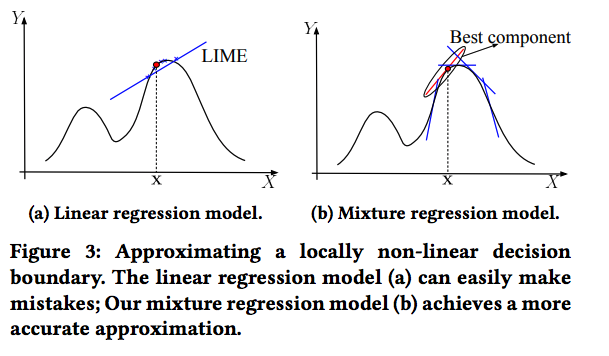
- 大部分的解释方法(比如LIME)假设决策边界是有局部线性特征的。但是,当这些局部决策边界不是线性的(对于大部分复杂网络而言),这些解释方法将导致严重的错误。Figure 3a 中展示了一个相应的例子。这个例子中,x附近的决策边界是高度非线性的。换而言之,这个例子中,线性的部分极度地约束于一个非常小的区域内部。我们通常用的取样方法非常容易就会采样到超越线性区域的样本点,从而使得一个线性模型很难拟合 x 附近的决策边界。我们的实验中发现这样简单的线性拟合会高度降低解释精度。
- 黑盒解释方法对于安全应用来讲是非常重要的,因为人们很少使用提供具体网络结构,参数,和训练数据的模型。虽然有些白盒解释方法可以强行在黑盒环境下使用,但是他们无可避免的会导致精度的下降。
总而言之,在这个工作中,我们尝试着提供专用于安全应用中的解释方法。我们的方法是一种黑盒方法,同时可以有效地支持诸如 RNN, MLP,和CNN的深度学习模型。更重要的是,这个方法实现了一个更高的精度来支持安全应用。
解释模型设计
我们的解释模型 为了实现以上的目标,我们设计并且开发了LEMNA。总体而言,我们将目标聚类器当成一个黑盒子,然后通过模型拟合来推导解释。为了提供高精度的解释,LEMNA需要一种全新的设计。首先,我们引入 Fused Lasso 来处理特征间的依赖关系。然后,我们将Fused Lasso 融入到一个混合线性模型中,以此来拟合局部非线形的决策边界,从而支持复杂的安全应用。接下来,我们首先讨论我们设计背后的原理。然后我们将讲述如果将这些设计整合成一个单独的模型,以此来同时处理特征依赖以及局部非线性。最后,我们介绍如何利用LEMNA来得到高精度的解释。
Fused Lasso是一种通常用来获取特征依赖的惩罚项,能有效的处理像RNN一类深度学习中的特征依赖。总体而言,Fused Lasso迫使LEMNA将相关/相邻的特征组合起来产生有意义的解释。接下来,我们介绍具体的细节。
为了从一个集合的数据样本中学习一个模型,机器学习算法需要最小化一个loss function L(f (x),y)。这个函数定义了预测结果和真实结果的不相似程度。比如说,为了从N个样本中学习到一个线性回归模型 f (x) = βx + ϵ,一个学习算法需要使用Maximum Likelihood Estimation (MLE) 来最小化如下的方程式:
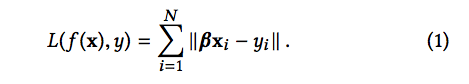
这里, Xi 是一个训练样本,被表示成一个多维的特征向量 (x1,x2,…xm)T。Xi 的标签表示为yi。向量β=(β1,β2,…βm )包含了这个线性模型的系数,而 ∥ · ∥ 是L2范式,来度量模型预测和真实结果中间的不相似程度。Fused Lasso是可以作为惩罚项引入学习算法中的任何损失函数。以线性回归为例,Fused Lasso表示为对于系数施加的约束:
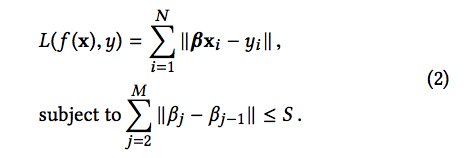
当一个学习算法最小化损失函数的时候,Fused Lasso 强制使得相邻特征间的系数之间的差距在一个S范围内。因此,这个惩罚项驱使一个学习算法对于相邻的特征赋予相同的权重。直观上来说,这个可以被认为是驱使一个学习算法聚合一组特征,然后根据特征群组来解释模型。安全应用,比如时间序列分析和代码序列分析,通常需要使用RNN来对特征之间的依赖性进行建模,由此得到的聚类器依据特征的共存来做出分类决策。如果我们用一个标准的线性回归模型(比如 LIME)来得到一个解释,我们将无法正确的拟合一个局部决策边界。这是因为一个线性回归模型将特征独立对待,无法捕捉到特征依赖。通过在拟合局部决策边界的过程中引入Fused Lasso, 我们期待得到的线性模型有如下形式:
![]()
在上面的形式中,特征被群组起来。因此,重要的特征有可能被选取成一个或者多个群组。具象的对这个过程进行建模的LEMNA可以推导出精确的解释,尤其是RNN所做出的决策。我们通过Figure 1中的情感分析的例子来解释这个思路。通过引入Fused Lasso, 一个回归模型将一起考虑相邻的特征(比如,一个句子中的相邻单词)。当我们推导解释时,我们的模型不再简单的抓住单词 “not”, 同时我们还能精确的抓住短语“not worth the price”来作为情感分析的解释结果。
Mixture Regression Model 使得我们可以精确的拟合局部非线形决策边界。如Figure 3b 所示,一个混合回归模型是多个线性模型的组合。它使得拟合更加有效:
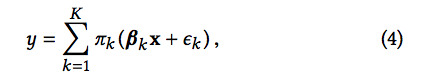
在上面的公式中,K 是一个超参数,代表着混合模型中线性部件的总个数。πk表示的是对应的部件的权重。
给定足够的数据,不论一个聚类器有着线性的还是非线性的决策边界,这个混合模型都可以近乎完美地拟合这个决策边界(使用一个有限集合的线性模型)。由此,在深度学习解释的问题中,这个混合回归模型避免了前面提到的非线性问题,从而得到了更精确的解释。为了更好的阐释这个思路,我们使用Figure 3中的例子。如该图所示,一个标准的线性拟合无法保证输入x 附近的样本仍然在线性局部空间内。这可能轻易导致一个不精确的拟合以及低精度的解释。我们的方法,如 Figure 3b所示,用一个多边的边界来拟合局部决策边界(每一条蓝色的直线代表了一个独立的线性回归模型)。其中最好的拟合是穿过数据点 x 的红线。由此,我们的拟合过程可以产生一个最好的线性回归模型来定位重要的特征。
模型构建 我们把Fused Lasso作为正则项加到mixture regression model中,为了估计模型的参数,我们需要求解如下的优化方程:
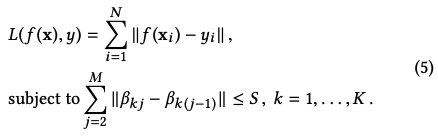
其中f是regression mixture model,β是参数。为了求解这个优化方程,我们需要使用期望最大算法(E-M)。为了使用EM算法,我们把模型等价改写为如下形式:
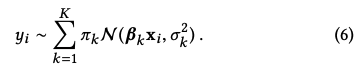
其中π,β,σ2是需要估计的参数。首先我们随机初始化参数,然后重复进行EM算法的E步和M步直到算法收敛。下面我们简单介绍一下具体算法。
从公式中可以看出,y服从一个由K个Gaussian distribution组成的distribution。每个Gaussian有自己的mean(β)和variance (σ2)。在每一次迭代中首先进行E步,我们把每个样本点分配到一个Gaussian。这里,我们使用的分配方法就是标准的EM算法的E步。完成E步后,根据新的数据分配结果,我们使用每一个Gaussian自己的数据更新它的mean和variance。更新variance的方法和标准EM相同,但是因为我们加了Fused Lasso的正则项在mean上,所以更新mean相当于求解如下优化方程:
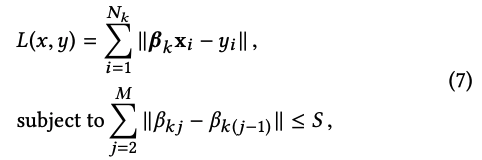
我们重复E步和M步直到模型收敛,进而输出模型参数。
应用模型到解释 我们现在介绍如何使用本文提出的模型解释神经网络的结果。具体来说解释过程分为以下两步:近似局部的决策边际和生成解释。
给定一个输入样本,生成解释的关键是近似深度学习模型的局部决策边际,从而获知聚类该样本的重要特征。为了实现这个目的,我们首先使用 [2] 中的方法生成一组人工样本。然后我们使用这些数据来模拟目标模型的局部决策边际。有两个可能的方法来实现模拟。第一种是使用一个混合回归模型进行多类分类。第二个是对每一个类使用一个混合回归模型。在本文中考虑到计算复杂度,我们使用第二种方法。
如前所述,对于一个给定的样本点,我们的解释是抓取目标模型聚类该样本时依据的重要特征。首先,我们通过上述的方法得到一个混合线性回归模型(mixture component)。这个线性回归的参数可以被视为特征的重要性。具体来说,我们把拥有大系数的特征作为重要的特征,同时选择最重要的一小组特征作为解释。
需要注意的是, 虽然LEMNA是为了非线性模型和特征相关性设计的,这不意味着LEMNA不能解释其他的深度学习模型(MLP和CNN)。事实上,LEMNA是可以根据所解释的深度学习模型调整的。比如,通过增加fused lasso的超参数S,我们可以放松这个正则项,进而使LEMNA适用于假设特征独立的深度学习模型。
实验与结果
为了验证LEMNA的有效性,我们将它应用到两个基于安全的深度学习上:恶意软件分类以及二进制代码逆向。本文中,由于空间有限,我们只介绍LEMNA在二进制代码逆向工程中的应用。
实验设计 二进制代码逆向将二进制代码逆向成汇编代码,对于恶意软件检测,软件安全加强,以及安全补丁都是至关重要的。多年来,二进制分析主要是通过有经验的安全分析员手工分析。最近,研究人员发现RNN在逆向工程中,比如发现函数开始位置,有很好的效果。考虑到检测函数开始位置的重要性(比如大部分的二进制代码逆向都需要知道函数开始位置),我们选择在此应用上测试LEMNA。我们按照 [4] 中的方法使用了2200个程序来训练RNN网络。我们将这些程序在O0, O1, O2, 和 O3这些优化级别下分别编译成二进制代码。由此,我们得到了四个不同的数据集,并且对每一个数据集训练了一个分类器。我们将这些数据集中的每一个二进制代码都表示成二进制序列。如 Figure 4所示,我们首先将这些二进制序列替换成数值序列,并且将每一个数值认为是一个特征。在训练中,每一个特征都有一个为“a function start”或者 “not function start”的标签。 我们同样依据 [4] 将长序列切分成最大长度为200的短序列,并且将最终生成的序列输入到RNN中。我们使用Theano作为后端,并且使用Keras来训练模型。我们使用70%的样本用于训练以及剩下的30%用于测试。
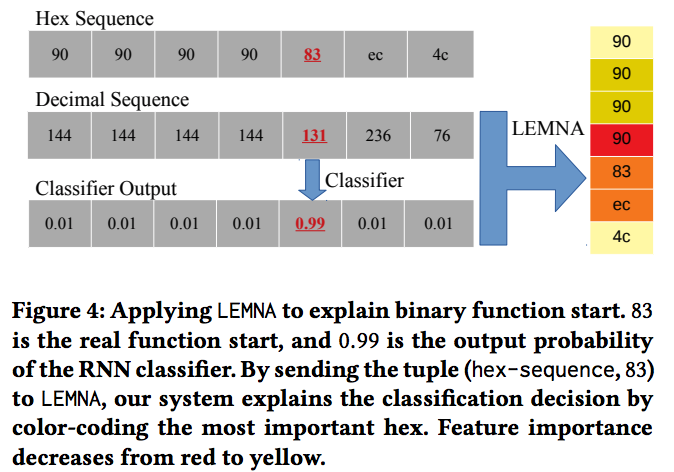
我们将上面提到的RNN作为LEMNA的目标模型。给定一个输入样本,LEMNA模拟这个目标聚类器然后解释聚类结果。这里,“解释”代表着一个输入样本中最重要的特征。对于“函数开始位置”聚类器,我们在Figure 4中展示了一个例子。给定一个样本数值序列以及RNN标定的函数开始位置(即“83”),LEMNA标定序列中拥有最大贡献的字节集合。在这个例子中,“83”是函数开始字节,而且LEMNA将函数开始位置前的“90”标记为RNN聚类的最重要的原因。LEMNA有三个可配置的超参数。首先为了拟合局部决策边界,我们构建N个数据样本来做模型拟合。第二个以及第三个参数分别是混合模块中的K以及Fused Lasso中的阈值S。在函数开始位置检测中,我们将这些参数分别设置为:N=500, K=6, S=1e − 4.
LEMNA的计算开销是相对比较低的。在函数开始位置检测中,解释一个给定的输入样本的开销大概是10秒钟。这个开销还可以通过并行进一步降低。
为了更直观的展示LEMNA的效果,我们选择了两个baseline来作为对比。首先,我们用现在最先进的黑盒解释方法 LIME [2] 作为我们比较的基础。为了公平的比较,在LIME中,我们同样的将500设定为拟合线性回归模型的样本基数。第二,我们用随机特征选择作为比较的基础。给定一个输入,这个方法随机地选择特征作为解释的结果。

精度评估 为了评估解释的精度,我们设计了一个两步的实验。第一步中,我们直接检测我们对于决策边界的局部拟合。这个极有可能会给出一个解释精度的初步估计。第二步中,我们对于解释精度进行端到端的评估。我们设计了三种精度测试来展示LEMNA标定的特征确实是聚类结果的主要原因。


为了保证结果的可解读性,我们将Fx约束在一个小的集合内。对于每一个分类器,我们将精度测试运行到所有的测试样本。给定测试样本中的一个实例,我们产生三个样本,依次对应着我们的三个精度度量方法。我们将这三个样本放进分类器中,然后观测positive classification rate (PCR)。注意这里的“positive”的意味是这个新样本的标签跟原样本一致。
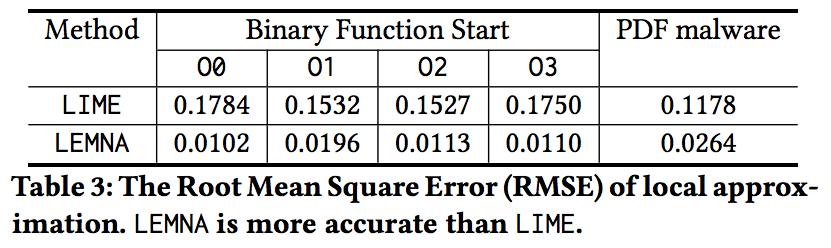
实验结果 我们的实验表明LEMNA在不同的精度指标上都比LIME和随机方法要好。如Table 3所示,LEMNA有着比LIME小几个量级的RMES。LIME给出的最好的结果是0.1532,然后它依旧比LEMNA最差的结果(0.0196)大了差不多十倍。 这个结果验证了我们的混合拟合模型可以构建一个精度更高的解释。
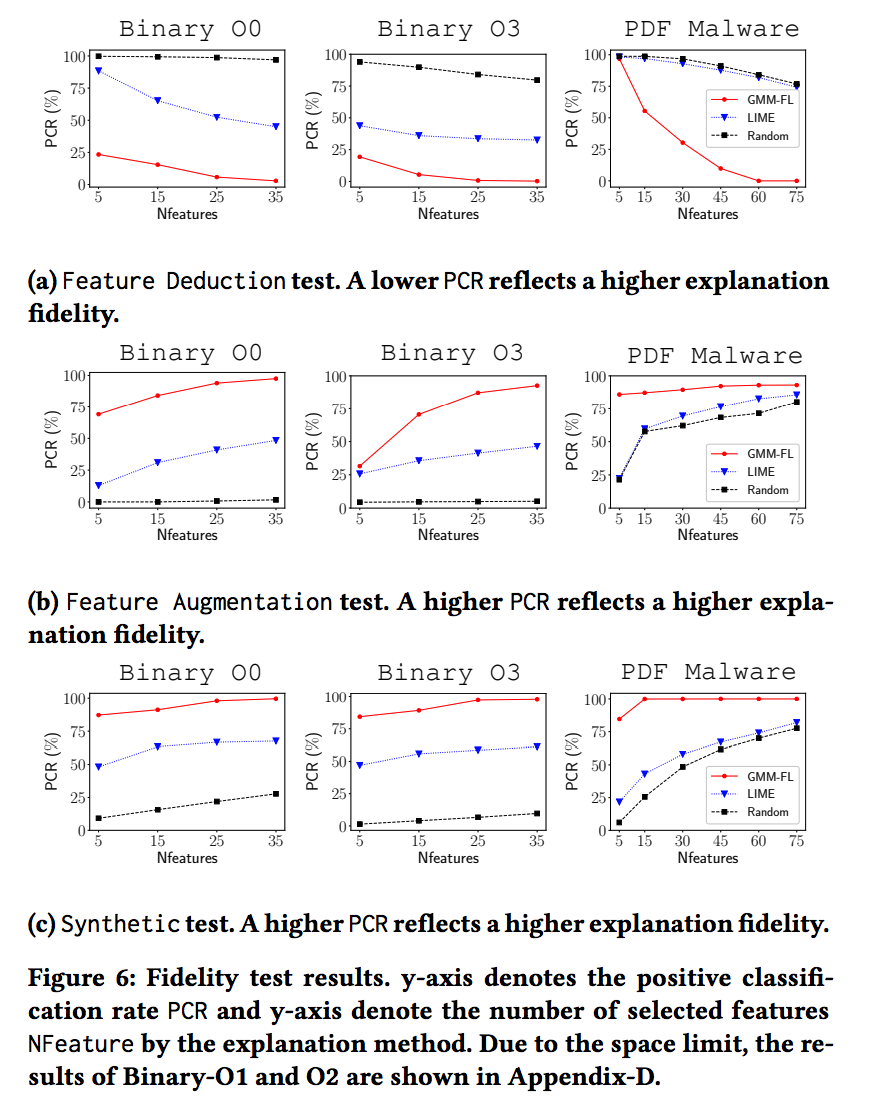
Figure 6a 展示了特征移除实验的结果。通过移除LEMNA标定的最重要的5个特征,函数开始位置的PCR降低到了25%甚至更低。考虑到这个聚类器极高的精度,这个剧烈的降低标志着这个小的特征集合对于聚类结果是及其重要的。
Figure 6b 展示了特征加强的结果。这个结果跟之前的测试是一致的:(1)通过加入一个小集合的特征,我们可以实现聚类结果的反转;(2)我们的方法显著的优于其他的两种方法。
Figure 6c 展示了在特征生成实验中,LEMNA有同样的优势。利用LEMNA挑选的重要特征,这些生成的样本极有可能会被归类成原始的标签。使用前五个最重要的特征,这些生成的样本有85%-90%的概率会被归类成原来的标签,标志着核心的特征已经被标定。
解释结果的应用
到目前为止,我们已经验证了解释结果的精度。接下来,我们简单介绍一些LEMNA解释结果的应用。我们通过case study来展示如何用我们的解释结果来帮助分类器建立可信度以及定位分类错误的原因。
理解模型行为 我们解释方法的主要应用是评估聚类器的可靠程度并且建立可信度。我们认为聚类器的可靠度和可信度并不一定来自于高的聚类精度。相反的,可信度更可能通过理解模型行为来建立。这里,我们从两个关键的角度来观测来评估聚类器的行为:(1)抓取常见的原则(2)发现新的知识。
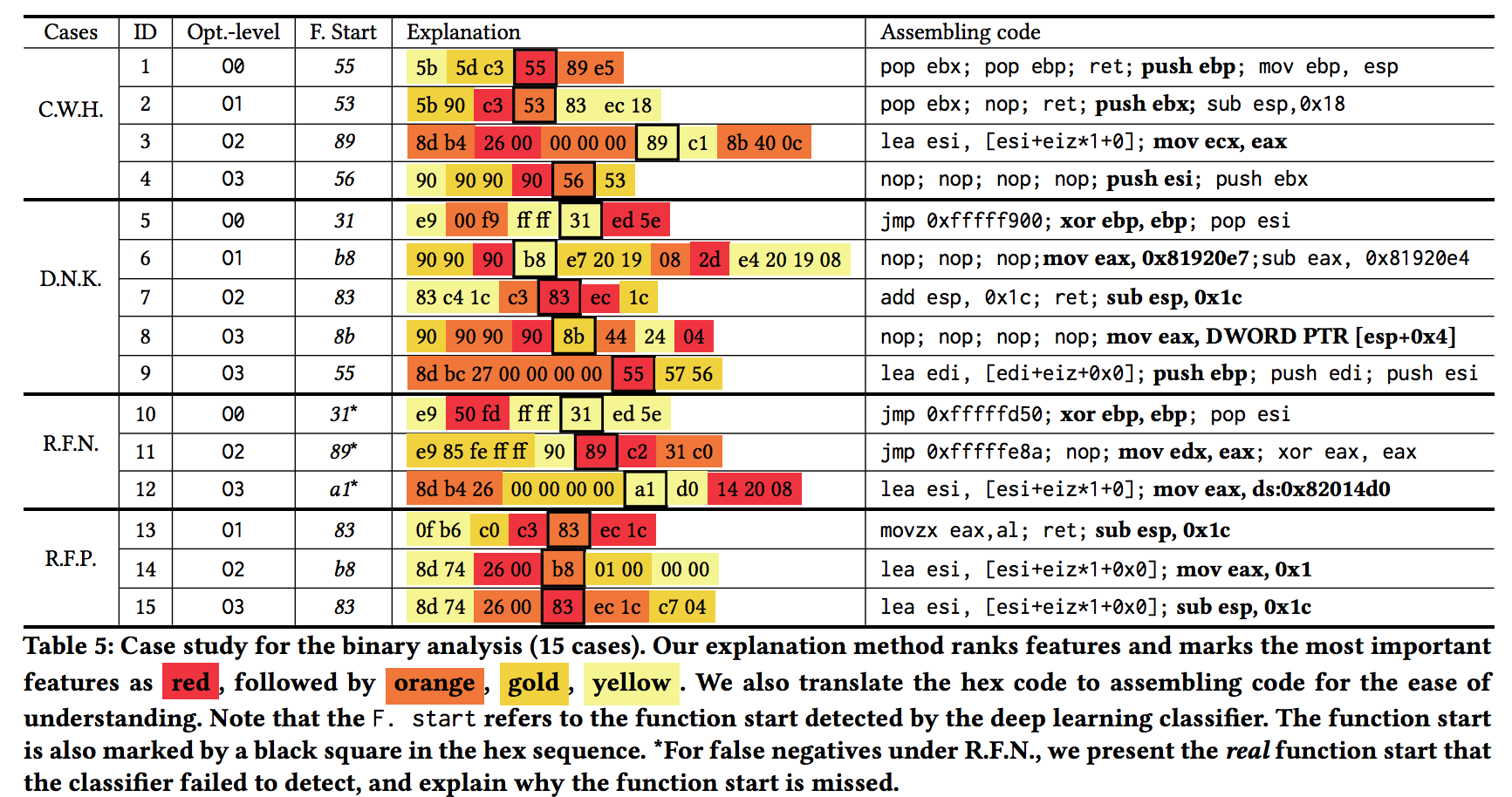
一个可靠的聚类器应该可以抓取应用场景中常见的原则。比如说,在二进制代码的逆向中,安全从业者已经积累了一系列有效的原则来寻找函数开始位置,其中有一些已经被当成了既定原则。比如说,ABI要求一个函数(如果使用栈帧指针的话)在开始的位置将父函数的栈帧指针放到栈上。这个导致了最常见的prologue [push ebp; mov ebp, esp]。 通过分析解释结果,我们发现了机器学习分类器成功的抓获了这些众所周知的原则。在Table 5中,我们展示了几个不同的有代表性的例子。我们以Case-1为例。在这个例子中,这个聚类器正确地检测到了函数开始位置“55”。LEMNA认为那些高亮的特征(即55附近的字节码)是聚类器做这个决策的原因。这个结果跟上面提到的原则(即 [push ebp; mov ebp,esp])是匹配的。这说明这个聚类器用一种合理的方式做出了决策。
除了匹配常见的原则外,我们还检测一个聚类器是否学习到了新的知识。我们认为,在安全应用中,新的知识需要能被领域内专家理解。在二进制分析中,很多潜在的有效的原则是对于特定函数有效的,而且他们很难通过手工完全总结。比如说,很多链接器插入的辅助函数通常有特殊的开始片段,而且这些片段基本不会在其他的地方出现 (比如, _start 函数通常从 [xor ebp, ebp; pop esi]开始)。手工总结这些规则是不现实的。但是,这些规则, 一旦被LEMNA,发现了,就可以给安全专家提供有效的知识补充。如Table 5所示,我们分析LEMNA的解释结果,并且发现这个聚类器的确学习到了新知识。以Case-5为例。在这个例子中,“31”被检测为函数开始位置,因为后续的字节( [ed 5e]. “ [31 ed 5e])” 对应着_start函数的开始位置 (即 [xor ebp, ebp; pop esi])。这个展示了我们的解释方法可以帮助总结某些函数使用的特殊的prologues 。
解决聚类错误 虽然深度神经网络高度精确,但是他们仍然可能产生错误。这些不应该被忽略,因为他们通常意味着训练不足并且这些不足可能在现实中被放大。我们的解释方法尝试寻找到错误聚类的原因。通过找到这些原因,我们希望能够启发解决这些错误的可行性方案。
对于二进制分析,这些聚类器不时的会错过函数开始位置。如Table 5所示(R.F.N),给定一个漏掉的函数开始位置,我们解释“为什么这些位置没有被标记为开始位置”。具体而言,我们将对象(代码序列,真实函数开始位置)输入LEMNA,并且选择那些导致函数没有被识别的特征作为解释。以Case-10为例,“[50 fd]” 对应着“[jmp 0xfffffd50]”,被标记为主要的聚类错误原因。这条指令几乎都出现在函数中间位置,导致聚类器认为后面的31不是函数开始位置。Case-10是一个异常样例,因为“[50 fd]”刚好出现在一个特殊区域.plt的末尾(后面紧跟着_start函数)。
Table 5也展示了聚类器错误的选择函数开始的例子。同样的,我们将对象(代码序列,错误的函数开始位置)输入到LEMNA,并且解释为什么这个错误的位置被选择。比如说,在Case-13中,LEMNA标定“c3”(对应着“ret”指令)。通常来说,“ret”位于函数的结尾使得函数退出,也就意味着后面的“83”将是一个新函数的开始位置。但是,这个例子是特殊的。因为“ret”被放到函数中间来实现优化。总结来说,LEMNA展示了这些错误大部分是由于这些重要的特征在绝大部分例子中是标定函数开始位置的,因此LEMNA会犯这样的错误。
结论
在这个工作中,我们设计了LEMNA,一种用于安全领域深度学习模型,有着高精度,适用于单样本聚类结果的解释方法。LEMNA将目标聚类器视为一个黑盒子然后通过一个Fused Lasso加强的混合回归模型来拟合聚类器的决策边界。通过对于安全应用的评估,我们展示了LEMNA有很高的解释精度。同时,我们展示了机器学习开发者以及安全专家如何从LEMNA的结果来理解模型行为以及定位分类错误。
参考文献
[1] Guo, Wenbo, et al. “Lemna: Explaining deep learning based security applications.” Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security. ACM, 2018.
[2] Ribeiro, Marco Tulio, Sameer Singh, and Carlos Guestrin. “Why should i trust you?: Explaining the predictions of any classifier.” Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining. ACM, 2016.
[3] Lundberg, Scott M., and Su-In Lee. “A unified approach to interpreting model predictions.” Advances in Neural Information Processing Systems. 2017.
[4] Shin, Eui Chul Richard, Dawn Song, and Reza Moazzezi. “Recognizing Functions in Binaries with Neural Networks.” USENIX Security Symposium. 2015.
个人简介
郭文博是Penn State就读的第二年博士生。他的研究方向是深度学习和计算机安全。现在主要的研究项目是提高深度学习的可解释性和应用机器学习到二进制分析中。他在机器学习和信息安全的顶级会议发表多篇论文,比如CCS,NeurIPS,KDD,并且获得CCS 2018最佳论文奖。同时他的多个工作被信息安全工业界顶级会议DEFCON收录,并且打入2018 geekpwn CAAD CTF总决赛。
Jun Xu is an Assistant Professor in the Department of Computer Science at Stevens Institute of Technology. He received his PhD degree from Pennsylvania State University and his bachelor’s degree from University of Science and Technology of China. Jun has been working on software and system security for many years and he has published a group of papers at top security conferences (e.g., CCS and USENIX Security). He specializes in vulnerability finding, vulnerability analysis, and vulnerability mitigation. His recent won the outstanding paper award at ACM CCS 2018. Jun is a recipient of RSA Security Scholar Award and USTC Guo-Moruo scholarship. Jun is looking for PhD students that share his interests (http://personal.psu.edu/~jxx13/).




