



论文标题:Towards the Detection of Inconsistencies in Public Security Vulnerability Reports(本文为Usenix Security2019录用)
论文作者:Ying Dong,Wenbo Guo,Yueqi Chen,Xinyu Xing,Yuqing Zhang,Gang Wang
作者单位:中国科学院大学,宾夕法尼亚州立大学,弗吉尼亚理工大学,JD安全研究中心
论文地址: https://www.inforsec.org/wp/wp-content/uploads/2020/04/sec19fall_dong_prepub.pdf
论文代码:https://github.com/pinkymm/inconsistency_detection
PPT下载: https://www.inforsec.org/wp/wp-content/uploads/2020/04/ogl.pdf
摘要
虽然公共漏洞库(如CVE和NVD)极大地促进了漏洞披露和缓解,但是随着漏洞库大量数据的积累,漏洞库信息的质量越来越受到了人们的关注。论文作者把CVE漏洞描述、CVE 参考报告分别与NVD进行了差异性测量,发现CVE漏洞描述、CVE 参考报告与NVD的平均严格匹配率只有 59.82%,NVD存在高估或低估软件版本的错误信息。
软件名称提取
为了量化差异性,需要从非结构化漏洞报告中提取出存在漏洞的软件名称和版本。由于漏洞报告的独特性,传统的NLP工具很难处理这个任务,论文作者提出了一个名为VIEM的系统来提取漏洞报告中的信息。
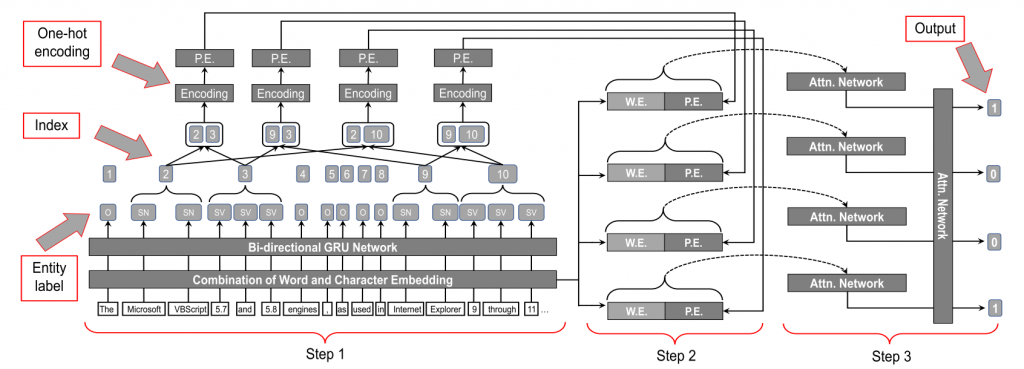
图1 模型结构
如图1所示,VIEM由NER(命名实体识别)模型和RE(关系抽取)模型组成。该模型可以识别出漏洞报告中存在漏洞的软件名称和版本。NER模型的输入是报告中的句子,比如句子“The Microsoft VBScript 5.7 and 5.8 engines, as used in Internet Explorer 9 through 11 …”,首先将它导入NER模型中,NER模型将输出句子中存在漏洞的软件名称和版本。在这个例子中, “Microsoft VBscript”、“Internet Explorer”是软件名称,“5.7 and 5.8”、“9 through 11”是版本。在模型内部,使用双向GRU来识别软件名称和版本,使用词向量和字符向量进行预处理,并使用字典进一步提高精度。在识别出软件名称和版本之后,把它们输入到RE模型中,识别出每个软件名称对应的软件版本,在例子中,把软件名称“Microsoft Vbscript”和软件版本“5.7 and 5.8”识别为一对,把软件名称“Internet Explorer”和软件版本“9 through 11”识别为一对。在RE模型中,使用one-hot encoding来对每种可能的软件名称版本对进行编码。然后将这个编码输入到一个层次注意力网络中,以预测出软件名称对应的软件版本。
通过训练内存崩溃这个类型漏洞的NER、RE模型来捕获这类漏洞的特征。然后,使用迁移学习为其他类型漏洞训练模型,比如SQL注入。这不仅缩短了训练时间,而且解决了某些类型漏洞训练数据不足的问题。
为了测量VIEM,作者收集了过去20年的7万多个漏洞报告。每个CVE ID所对应的网页还包含外部漏洞报告的链接。论文作者的研究重点是5个具有代表性的来源网站,这些漏洞网站包括SecurityTracker、SecurityFocus、ExploitDB、Openwall以及 SecurityFocus 论坛。另外,他们还手工标记了大约2000个漏洞报告来训练模型。在内存崩溃这种漏洞上训练NER和RE模型,在ground-truth数据集中,有接近3500个CVE ID,以8:1:1的比例对模型进行训练、验证和测试。
经过测试,NER、RE模型表现得很好,准确率达到了97.6%,而之前最先进技术的准确率不超过90%。
对于迁移学习,论文作者使用内存崩溃作为教师模型,其他类型漏洞作为学生模型。对于每个学生模型,用145个漏洞报告作为ground-truth数据集,以1:1的比例进行预训练和测试。在内存崩溃外的其他12种类型漏洞模型的平均准确率通过迁移学习把准确性从87.6%提高到了90.4%。
差异性测量
在使用VIEM提取出存在漏洞的软件名称和版本之后,论文作者进行了大规模的差异性测量。
首先定义了差异性的测量标准。差异性测量结果分为严格匹配(两个版本集合完全相同)和松散匹配(一个版本集合是另一个版本集合的子集)。使用这两个参数来测量差异性,并得到了一些有趣的发现。
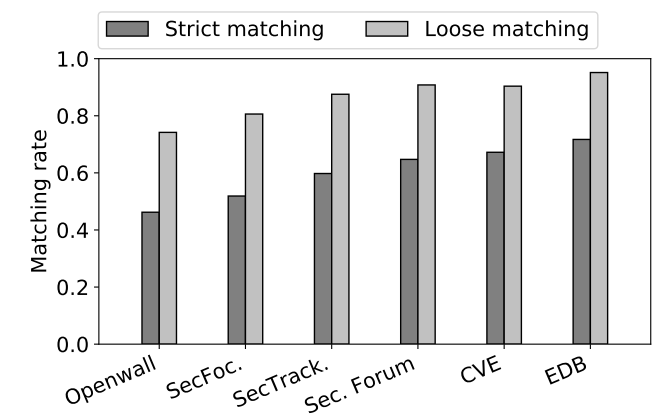
图2 不同信息源的匹配率
通过把各个网站与NVD进行对比,发现差异性是普遍存在的。从图2中看到,对于严格匹配来说,匹配率最高的是ExploitDB,它的匹配率不超过80%。即使使用松散匹配,匹配率也没有达到100%。此外,论文作者还研究了为什么ExploitDB优于其他漏洞网站。他们发现,ExploitDB的大多数漏洞报告都是在NVD条目创建之后发布的。
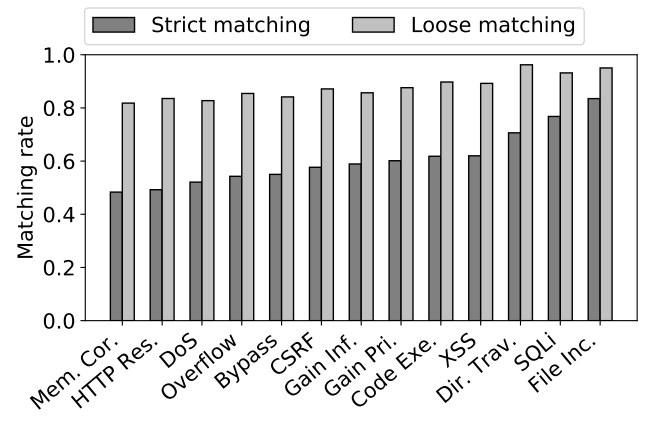
图3 不同类型漏洞的匹配率
论文作者研究了不同类型漏洞的匹配率,发现每种类型的漏洞都存在差异性。如图3所示,虽然松散匹配率仍然相似,但严格匹配率存在明显差异。“SQL 注入” 和“文件包含”具有最高的严格匹配率,数值超过了75%。“内存崩溃”的类型具有低得多的严格匹配率,只有48%。进一步人工验证表明,“内存崩溃”漏洞通常比“SQL注入”和“文件包含”类型的漏洞更复杂,因此需要更长的时间来重现和验证。因此,NVD可能随着时间的推移,并未加入新发现的存在漏洞的版本。

图4 高估和低估的例子
把松散匹配细分为高估和低估,在图4的例子中,把NVD和CVE的CVE-2005-4134进行比较,NVD 高估了图4软件“Mozilla Firefox”和“Netscape Navigator” 的版本,因为NVD列出的版本比CVE列出的要多。相反,对于软件“K-Meleon”,NVD 低估了存在漏洞的软件版本范围。
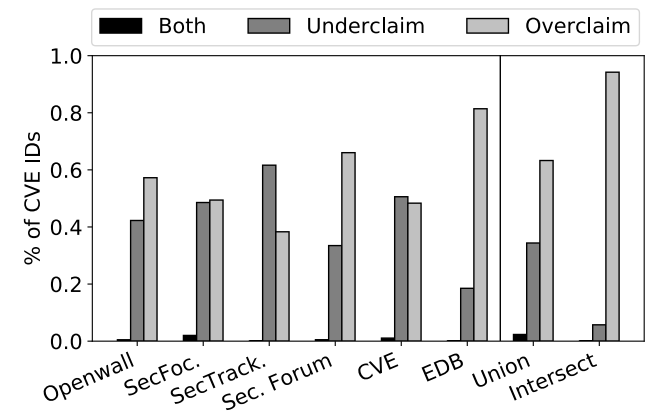
图5 高估和低估
图5中给出了松散匹配中,高估和低估的NVD条目所占的比例。此分析中不包含严格匹配的软件名称版本对。论文作者发现NVD条目可能会高估存在漏洞的版本,这是合理的。因为NVD理应搜索不同的漏洞信息源以使得NVD条目及时更新,所以NVD条目可能覆盖更多存在漏洞的版本号。即使对5个网站和CVE摘要中的存在漏洞的版本取并集,NVD仍然有覆盖更多存在漏洞的版本的情况。更有趣的发现是,与每个外部信息源相比,NVD仍然会存在低估存在漏洞版本的情况。这意味着NVD要么延迟更新数据条目,要么不能及时追踪外部报告的漏洞数据更新。只有小部分NVD条目同时包含低估和高估的版本。
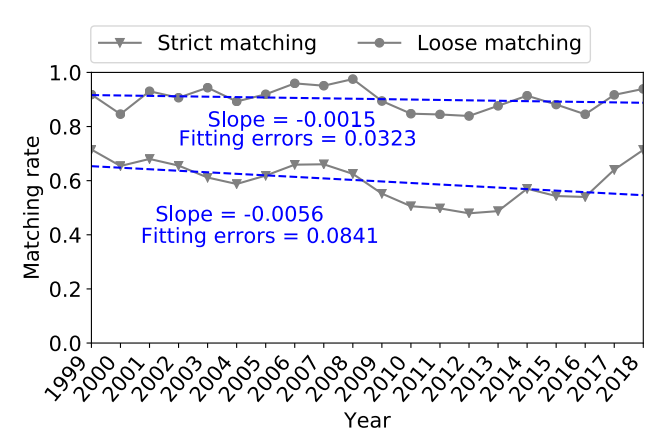
图6 匹配率随时间的变化情况
论文作者测量了一致性随时间的变化情况,根据图6蓝色虚线可以发现,NVD与其他 6 个信息源之间的一致性水平随着时间的推移而逐渐降低。对两种匹配率进行线性回归,发现两者都为负斜率。结果表明,在过去的20年中,整体的一致性随着时间的推移而下降。但是,近几年 (2016年至2018年)整体的一致性水平开始升高,这是一个好兆头。
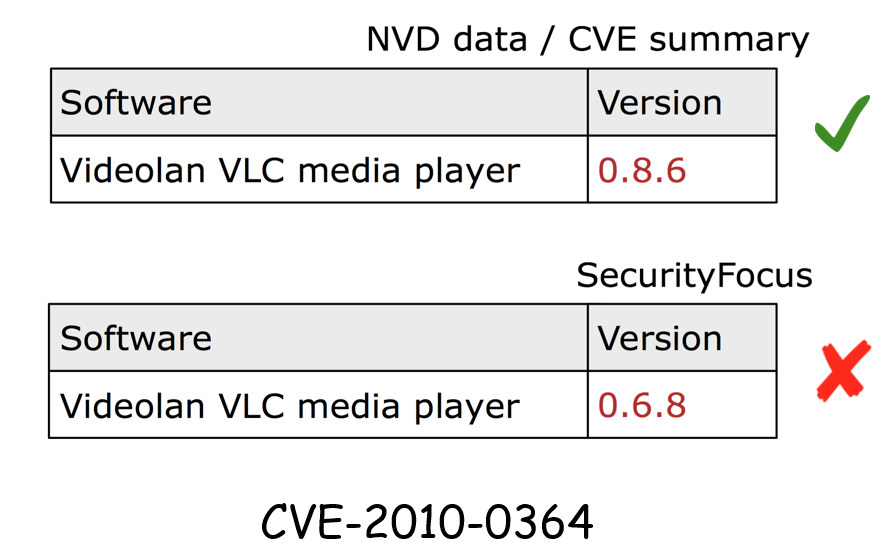
图7 各漏洞库的CVE-2010-0364的软件名称和版本
论文作者找出了造成差异性的一些原因,其中一个原因是笔误。在图7中,正确的版本是0.8.6,然而SecurityFocus将版本写成了0.6.8。笔误是其中一个原因。

图8 各漏洞库的CVE-2006-6516的软件名称和版本
另一个原因是NVD的大多数报告在创建后很少更新。作者随机选择了5000 个存在差异性的CVE ID,发现66.3%的NVD报告从未更新。比如在图8中,在2010年,Securityfocus添加了存在漏洞的新版本1.11。然而,NVD仍然认为1.16是存在漏洞的唯一版本。
为了更好地理解信息差异性造成的影响,论文作者做了一个案例研究,收集了7个漏洞,覆盖了47个报告,报告来源不限于之前介绍的5个漏洞报告网站。在这185个版本中,只有64个版本被确认是存在漏洞的。论文作者发现了12个存在漏洞的新版本,这些版本并没有被漏洞报告网站收录。
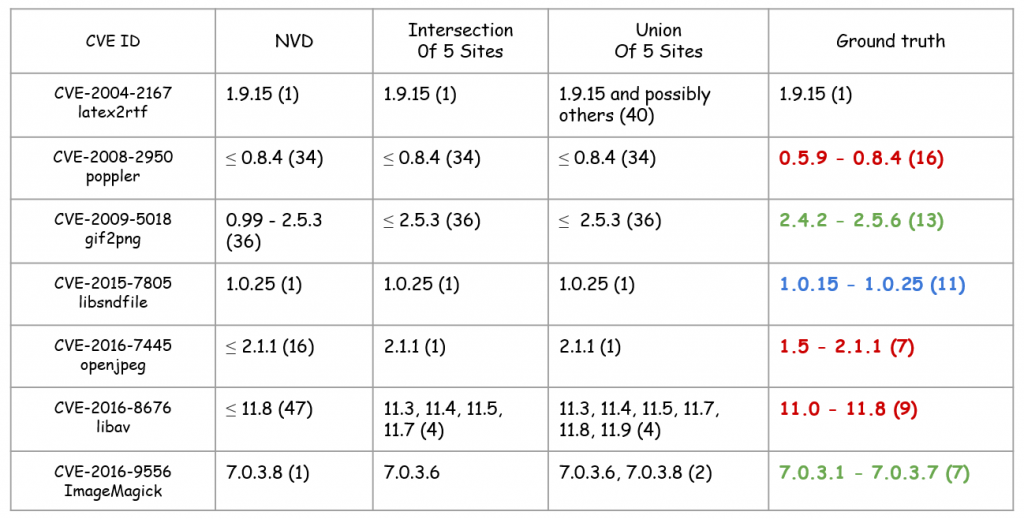
图9 案例研究
通过人工验证确认了ground-truth数据,并把数据与NVD进行了比较。图9中的红色字体表示高估,蓝色表示低估,绿色表示两个版本集合都有对方不包括的版本。一方面,“低估” 的问题可能会导致存在漏洞的软件系统的漏洞未被完全修补,因为一些存在bug的版本没有被记录。另一方面,“高估”的问题可能会导致在进行风险评估时,浪费安全分析人员的大量人工工作,让他们徒劳地测试一些不存在漏洞的软件版本。另外,还将ground-truth和5个网站的交集、并集分别进行了比较,仍然存在高估低估的问题。
总结
在本文中,论文作者设计和开发了VIEM来自动化地提取存在漏洞的软件名称和版本,然后将VIEM应用于大规模的差异性测量中,结果表明差异性的信息是普遍存在的。最后,作者还做了一个案例研究,表明不一致的信息有严重的安全影响。
作者简介:
欧国亮,中国科学院大学国家计算机网络入侵防范中心硕士研究生,研究方向为信息安全与机器学习。




