



编者按
2022年5月,由网络安全研究国际学术论坛(InForSec)汇编的《网络安全国际学术研究进展》一书正式出版。全书立足网络空间安全理论与实践前沿,主要介绍网络和系统安全领域华人学者在国际学术领域优秀的研究成果,内容覆盖创新研究方法及伦理问题、软件与系统安全、基于模糊测试的漏洞挖掘、网络安全和物联网安全等方向。全书汇总并邀请了近40篇近两年在网络安全国际顶级学术议上发表的论文(一作为华人),联系近百位作者对研究的内容及成果进行综述性的介绍。从即日起,我们将陆续分享《网络安全国际学术研究进展》的精彩内容。
本文根据论文原文“PalmTree: Learning an Assembly Language Model for Instruction Embedding”整理撰写。原文发表于 ACM CCS 2021。本文较原文有所删减,详细内容可参见原文。
一、介绍
近年来,有大量的研究工作将深度学习理论应用于各种二进制代码分析任务中,包括函数边界识别、二进制代码相似性检测、函数原型推断、值集分析(VSA)、恶意代码分析等任务。在上述任务中,深度学习展示出了显著优于传统程序分析和机器学习方法的效果。
当我们将深度学习应用于二进制代码分析时,需要回答的第一个问题是:应该将什么形式的输入数据送入深度神经网络模型中?总体来讲,存在 3 种选择:一是将原始字节流直接输入神经网络中(如 αDiffff、DeepVSA、MalConv);二是输入人工设计的特征(如 Gemini、Instruction2Vec);三是使用如 word2vec 的某种表示学习方法,将每一个汇编指令自动映射为一个向量表征,然后再将该向量表征(或称嵌入)输入下游模型中。
和前两种选择相比,自动进行指令级别的表征学习是更有效的方法。这是由于其无须对特征进行人工设计,人工设计特征需要丰富的领域知识,过程枯燥且易出错;指令表征能够学习到高层次的特征而不仅仅是句法信息,并且能够对下游任务进行更好的支持。为学习汇编指令的表征,研究者们将二进制汇编代码视为自然语言文档,并使用自然语言处理中的算法(如 word2vec 和 PV-DM)将指令映射到向量空间中。
虽然近期在指令表征(或称指令嵌入)学习方面取得了令人瞩目的进展,但仍存在一些没有解决的问题,这些问题可能会严重影响指令嵌入的质量。这些问题具体如下。
首先,已有方法忽略了汇编指令内部的复杂结构。例如,在 x86 汇编代码中,操作数的个数可能从 0 到 3;1 个操作数可以是 1 个 CPU 寄存器、1 个内存地址表达式、1 个立即操作数等;一些指令也存在隐性操作数等。然而,已有的方法或者忽略上述结构信息,将整个指令视为自然语言中的 1 个词(如 InnerEye 和 EKLAVAYA);或者仅仅考虑了简单的指令格式(如 Asm2Vec)。
其次,已有方法通常使用控制流图(CFG)来提取指令之间的上下文信息(如 Asm2Vec和 InnerEye)。但是由于编译器优化的存在,控制流上的上下文信息可能存在噪声,因此无法反映指令之间真正的依赖关系。
另外,近年来,预训练的深度学习模型在计算机视觉和自然语言处理等领域得到了长足的发展。预训练的出发点是,随着深度学习的进展,模型的参数快速增加,因此需要大规模的数据集以充分训练模型参数并避免过拟合。大规模、无标注的语料库和自监督训练任务的预训练模型(PTMs)在自然语言处理等领域的使用得到了广泛的关注。自然语言处理领域代表性的深度预训练语言模型包括 BERT、GPT、RoBERTa 和 ALBERT 等。考虑到包括汇编语言在内的编程语言的“自然性”,预训练一个汇编语言模型将对不同的二进制代码分析任务具有重要且深远的意义。
为了解决指令表征学习中存在的问题,并刻画汇编指令的本质特征,在本文中,我们提出了面向通用指令表征学习的预训练的汇编语言模型,并称之为 PalmTree(Pre-trained Assembly Language Model for InsTRuction EmbEdding)。PalmTree 基于 BERT 模型,但使用了多个新设计的预训练任务,这些任务有效地利用了汇编语言的内在特点。PalmTree 使用了 3个预训练任务以更好地描述汇编语言的特点,例如由编译器优化带来的指令重排序和长距离的数据依赖关系。这 3 个预训练任务工作于不同的粒度,以使 PalmTree 有效地描述汇编指令的内部格式、控制流依赖的上下文信息,以及指令间的数据依赖关系。
我们设计了一系列内部评估和外部评估,以系统性地评价 PalmTree 和其他指令嵌入模型。实验结果表明,和已有的模型相比,PalmTree 在内部评估中有最好的性能。在外部评估中,PalmTree 也优于其他指令嵌入模型,并显著地提升了下游应用的效果。实验结果表明,PalmTree 能够有效生成有助于不同下游二进制代码分析任务的高质量指令嵌入。
二、背景
在本节中,我们首先总结指令嵌入方面的已有方法及知识,接着讨论已有方法存在的问题。
1. 已有方法
(1)原始字节编码。指令嵌入最为基础的方法是将简单的编码规则应用于每个指令的原始字节,然后将编码后的指令输入深度神经网络模型中。其中的一种方法叫作独热编码(one-hot encoding),即将每字节转为一个256维的向量,其中一维为1,其余各维均为0。MalConv和DeepVSA分别使用这种方法进行恶意代码分类和粗粒度的值集分析。
总体而言,此类方法较为简单和有效,因为其并不需要反汇编过程,而反汇编一般具有较高的复杂度。然而,其缺点是没有提供关于每个指令的语义层次的信息。例如,在分析过程中无法得知每一个指令的类型和相关的操作数。深度神经网络有可能学习到一些语义层次的信息,但是,深度神经网络很难完整地理解所有指令的语义信息。
(2)反汇编指令的手动编码。考虑到反汇编代码包含关于一个指令的更多语义信息,这种方法首先反汇编每个指令,其次对反汇编代码的特征进行编码。
和原始字节编码相比,此类方法能够描述关于指令操作符和操作数的更多信息。然而,此类方法无法包含每个指令的高层语义信息。例如,此类方法将每个操作符同等对待,因而此类方法无法描述如下情况:add 和 sub 均为算术操作,因此和call这一控制转移操作相比,前两者应更为相似。虽然可以通过人工设计对一些高层语义信息进行编码,但这一过程往往需要大量的领域专家知识,并且很难保证其正确性和完备性。
(3) 基于深度学习的编码方法。受到近年来在其他领域(如自然语言处理)中表征学习的启发,此类方法自动对每一个指令生成包含高层次语义信息的表征。学习到的表征能够被任意的下游二进制代码分析任务使用,从而实现较高的准确度和可泛化性。
多项研究曾尝试使用word2vec来自动学习指令级别的表征(或称嵌入),并在代码相似性检测、函数原型推断等任务中应用。此类方法的主要思想是将每一个指令看作一个自然语言文档中的词,而将每一个函数看作一个文档。通过将word2vec算法(包括Skip-gram和CBOW模型)应用于反汇编代码,我们将能够得到每一个指令的数值化向量。
2. 已有方法存在的问题
虽然基于深度学习的编码方法在近年来取得了显著进展,但仍存在以下问题和挑战。
(1) 复杂和多变的指令格式。汇编指令,特别是CISC架构下的汇编指令,通常具有多变的格式和较高的复杂性。图1给出了x86架构下的多个指令的例子。

图1
在x86架构中,一个指令可以有0~3个操作数。操作数可以是CPU寄存器、内存地址表达式、立即操作数等。一个内存操作数通过表达式base+index×scale+displacement进行计算。其中base和index是CPU寄存器,scale是一个常数,displacement可以是常数或字符,并且所有字段都是可选的。因此,指令的内存地址表达式存在很多变化,一些指令还存在隐式操作数。算术指令隐式地改变了EFLAGS,而条件跳转指令将EFLAGS作为一个隐式的输入。
一个有效的指令级别的表征需要理解上述这些关于每个指令的细节信息。但是,已有的基于深度学习的编码方法并不能很好地处理上述复杂性。例如,被多项研究使用的word2vec将整个指令看成一个词,从而完全忽视了上述复杂的指令内部结构。
Asm2Vec对指令内部进行了有限的分析,它认为一个指令由一个操作符和最多两个操作数组成。一个有复杂表达式的内存操作数被认为是一个词符(token),因此其无法理解内存地址的计算过程。同时,Asm2Vec没有考虑其他的复杂性因素,如前缀、第三个操作数、隐式操作数、EFLAGS等。
(2)存在噪声的指令上下文。指令上下文的定义为“在控制流图中目标指令之前和之后的少数指令”。上下文中的指令通常和目标指令存在一定的关系,因此能帮助我们推断目标指令的语义。
上述假设总体而言是成立的,然而,编译器优化往往会破坏这一假设,以最大化指令级别的并行化程度。编译器优化选项(如GCC中的“-fschedule-insns”“-fmodulo-sched”“-fdelayed-branc”)为避免指令执行流水线中的阻塞,会将寄存器和内存地址的加载操作和其最后一次存储操作相远离。这种优化通过在操作之间插入无关的指令来实现。
以图2所示的代码段为例,第10行的test指令和其前后的call指令、mov指令是没有关系的。test指令将其结果存入EFLAGS,因此被编译器提前到了mov指令之前,以使其远离第14行的je指令。而第14行的je指令将会加载第10行的test指令存入EFLAGS的结果。通过这一示例,我们可以得知,控制流图中的上下文关系可能会由于编译器优化而存在噪声。

图2
三、PalmTree模型设计
为应对在指令嵌入方面存在的问题和挑战,我们提出了PalmTree模型。PalmTree是一种新的指令嵌入框架,其能够自动学习汇编代码的语言模型。PalmTree基于BERT模型,并融合了以下重要的设计考虑。
(1)为了描述指令内部的复杂格式,我们使用了更细粒度的策略对汇编指令进行分解:我们将每一个指令看作自然语言处理中的一个句子,并将其分解为基本的词符。
(2)为了训练深度神经网络以使其理解指令内部的结构,我们使用了近期在自然语言处理领域提出的训练任务:掩码语言模型(MLM)。该训练任务训练语言模型预测指令中被掩码的(即被隐藏的)词符。
(3)我们希望训练该语言模型,以使其捕捉到指令之间的关系。为此,我们设计了一个新的训练任务,该训练任务受到了word2vec和Asm2Vec的启发。在Asm2Vec中,其模型试图通过预测在控制流上的滑动窗口中的两个指令的共现性来学习指令的语言。我们将该训练任务称为上下文窗口预测(CWP),该任务类似于BERT模型中的下一句预测(NSP)。具体而言,如果两个指令i和j处于控制流的同一个滑动窗口中,并且i出现在j之前,我们称i和j有上下文关系。值得注意的是,和NSP相比,上述关系更为松弛。在NSP中,两个句子需要彼此紧邻。这样的设计选择是由于编译器优化的存在,指令可能被重排,因此紧邻的指令可能并没有语义上的相关性。
此外,和自然语言不同,指令的语义被清楚地记录在汇编语言中。例如,每个指令的源操作数和目的操作数都被清晰地表示。因此,指令之间的数据依赖(或定义使用)关系都被清晰地记录,而且不会被编译器优化干扰。基于这样的事实,我们设计了另一个训练任务,并称其为定义使用预测(DUP),以进一步提升我们的汇编语言模型。总体而言,在该训练任务中,我们训练语言模型来预测两个指令间是否存在定义使用关系。
图3展示了PalmTree模型的整体设计,其由3 个模块组成:指令对采样(instruction pair sampling)、词符化(tokenization)和汇编语言模型。
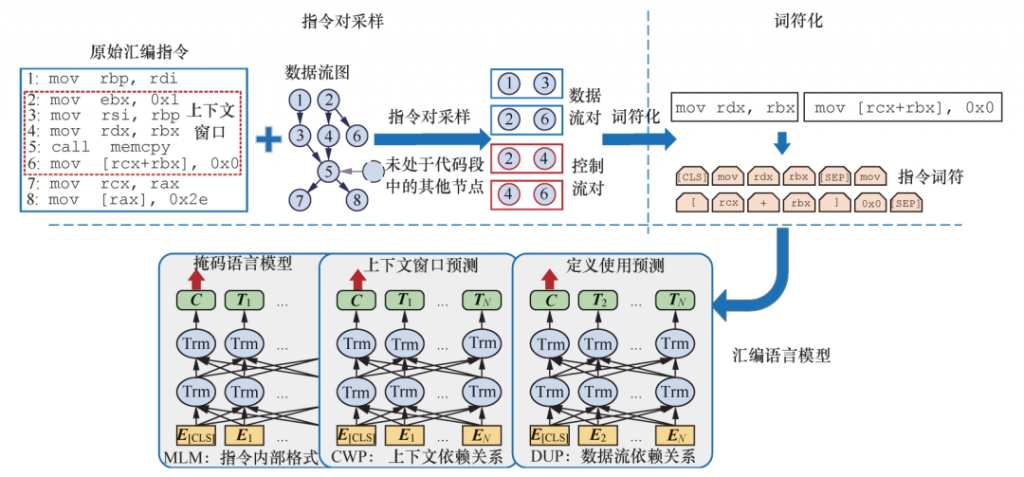
图3
该系统中的主要模块,即汇编语言模型(assembly language model)基于BERT模型。在训练过程后,我们使用BERT模型的倒数第二层的隐藏状态(hidden states)的均值池化(mean pooling)作为指令嵌入的结果。指令对采样模块主要负责从二进制代码中基于控制流和数据流关系采样指令对。
在词符化模块中,指令对被分割为词符。词符包括操作符、寄存器、立即数、字符串和符号等。特殊的词符如字符串和内存偏移量,将在这一模块中被编码和压缩。之后,我们使用本节提及的3个训练任务来训练BERT模型:MLM、CWP和DUP。在模型被训练之后,我们使用训练后的语言模型生成指令嵌入。总体来说,词符化策略和MLM有助于我们应对复杂多变的指令格式,而CWP和DUP有助于我们应对存在噪声的指令上下文。
在本文的后续部分,我们将对PalmTree和已有的指令嵌入模型进行评估。为了更好地评估3个训练任务对PalmTree的贡献,我们提供了3种PalmTree的模型设置。
■ PalmTree-M:仅使用MLM训练的PalmTree模型。
■ PalmTree-MC:使用MLM和CWP训练的PalmTree模型。
■ PalmTree:使用MLM、CWP和DUP训练的完整PalmTree模型。
四、模型评估
在本文中,我们设计了一个完备的评估框架,以系统性地评价PalmTree和其他的指令嵌入基线方法。评估可以分为两大类:内部评估和外部评估。
1.内部评估
(1)离群点检测。在此项内部评估中,我们随机构造一个指令集合,其中有一个指令为离群点。也就是说,这个指令和集合中的其他指令有显著不同。为了检测该离群点,我们计算集合中任意两个指令的向量表示的余弦距离,并选出和其他指令距离最远的指令。我们设计了两组离群点检测实验,其中一组是针对操作符的离群点检测,另一组是针对操作数的离群点检测。
基于x86汇编语言参考手册,我们将指令根据其操作符分为12类。我们构造了50000个指令集合,每个指令集合包括了4个来自同一类操作符的指令和1个来自其他类的指令。类似地,我们也根据操作数对指令进行了分类。总体而言,我们根据操作数个数和操作数类型对操作数列表进行分类。我们创建了涵盖10类的50000个指令集合,在每一个集合中,4个指令来自同一类,1个指令来自其他类。离群点检测内部评估的实验结果如表1所示。
表1
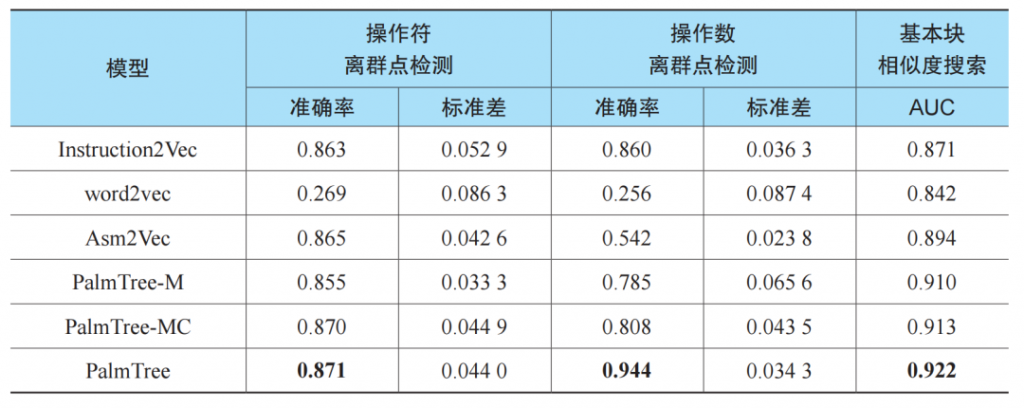
表1的第一列和第二列分别展示了操作符离群点检测和操作数离群点检测的准确率及其标准差。我们可以得到如下结论。
■ word2vec在两项实验中均表现较差,这是由于其没有考虑指令的内部结构。
■ 作为一种人工设计的指令嵌入方法,Instruction2Vec在两项实验中均有较好的表现,因为其的确考虑到了不同的操作符和操作数种类。
■ Asm2Vec在操作符离群点检测中的表现略优于Instruction2Vec,但是在操作数离群点检测的表现远差于Instruction2Vec,这是由于其对操作数的建模没有达到足够细的粒度。
■ 尽管PalmTree-M和PalmTree-MC并没有显著地优于Asm2Vec和Instruction2Vec,但PalmTree在两项实验中均取得了最好的结果,证明这一自动学习到的表征能够有效地区分操作符和操作数间的语义差别。
■ 3个预训练任务均对PalmTree的最终性能有所贡献。特别地,预训练任务DUP在两个模型中均显著提升了模型的准确率,说明定义使用的确有助于语言模型的训练。
(2)基本块相似性搜索。在此项内部评估中,我们通过对其内部的指令嵌入进行平均,计算每一个基本块(即1个仅有1个入口和1个出口的指令序列)的嵌入。给定1个基本块,我们通过计算两个基本块嵌入的余弦距离来寻找和其语义等价的基本块。我们使用openssl-1.1.0h和glibc-2.29作为测试集(这两个项目没有包括在我们的训练集中)。我们使用O1,O2和O3优化等级对上述两个项目进行编译。Instruction2Vec、word2vec、Asm2Vec和PalmTree在基本块相似度搜索中的ROC曲线如图4所示。
表1的第三列给出了每一种嵌入模型的AUC评分。基于以上结果,我们有如下观察。
■ word2vec的表现依然最差。
■ 人工设计的嵌入模型Instruction2Vec的表现优于word2vec。
■ Asm2Vec有相当好的表现,但是依然比PalmTree的3种配置要差。
■ 和其他基线方法相比,3种配置的PalmTree有更好的AUC得分,同时,随着预训练任务的增加,PalmTree的性能也越来越好。
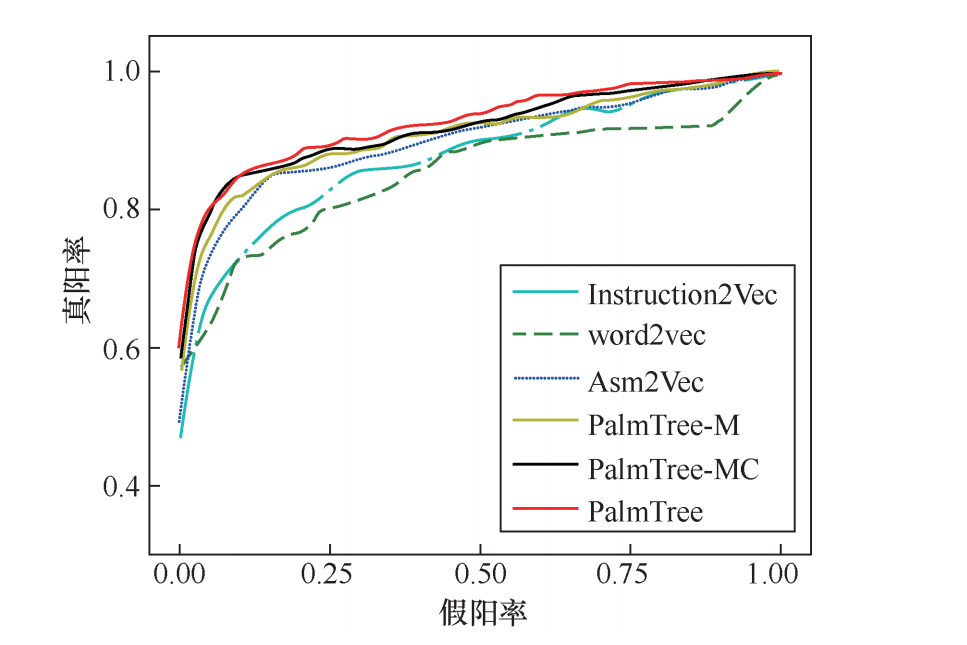
图4
结论:PalmTree在所有的内部评估中均有最好的表现,说明其自动学习到了汇编语言的语义;在不同的配置之间性能的增加,也展示了每种预训练任务都对模型的最终表现有着积极的贡献。
2.外部评估
外部评估反映了指令嵌入模型能够被下游机器学习算法在一个或多个任务中使用的能力。我们选择在二进制代码分析领域的3个下游任务,分别是二进制代码相似性检测、函数原型推断和值集分析。
(1)二进制代码相似性检测。Gemini是一个基于神经网络的跨平台二进制代码相似性检测模型。该模型基于Structure2Vec,并且将属性控制流图(ACFG)作为输入。在每一个ACFG中,一个节点表示一个基本块的由人工构造规则形成的特征向量。
在本实验中,我们测试当使用Intruction2Vec、word2vec、Asm2Vec和PalmTree分别作为输入时Gemini的表现。此外,我们使用独热向量加嵌入层作为另一个基线方法。该嵌入层将参与Gemini的训练。图5展示了我们如何将不同的指令嵌入模型应用于Gemini。在实验中,我们也将Gemini原有的基本块特征作为另一个基线模型。
为真正评估Gemini模型在不同输入下的可泛化性,我们将被Clang编译的binutils-2.26、binutils-2.30,以及coreutils-8.30作为训练集(包含237个二进制文件),而将被GCC编译的openssl-1.1.0h、openssl-1.0.1和glibc-2.29.1作为训练集(共包含14个二进制文件),也就是说测试集、训练集、编译器均不相同。表2展示了当不同模型被用来生成其输入时Gemini的AUC评分。
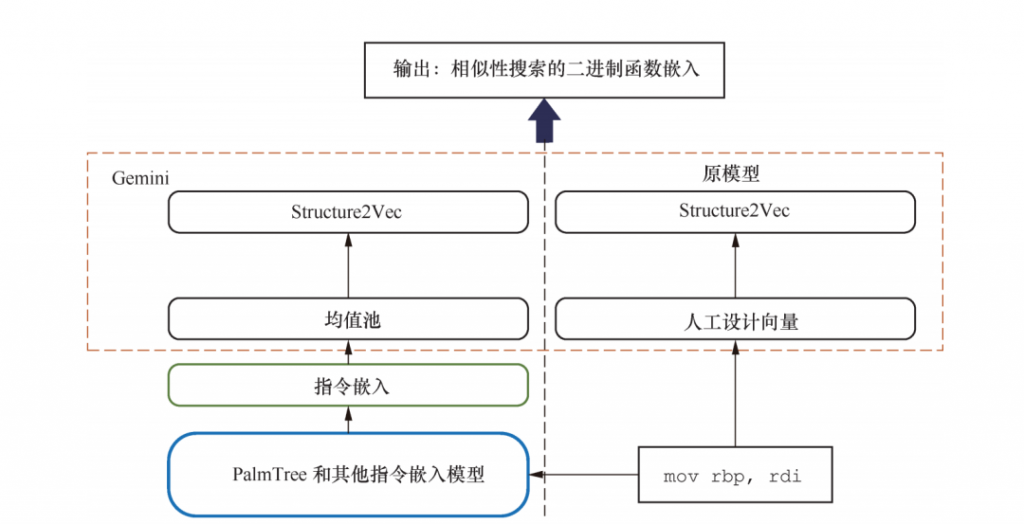
图5
表2
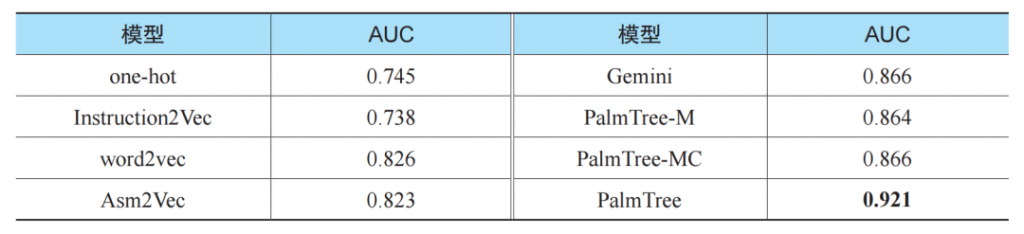
基于表2,我们有如下观察。
■ 人工设计的嵌入模型Instruction2Vec和独热向量的表现均较差,说明人工设计和选择的特征可能并不适用于一些下游任务(如Gemini)。
■ 虽然测试集和训练集完全不相同,但PalmTree依然具有较好的表现,并且优于其他模型,这一结果说明PalmTree可以有效地提升下游任务的可泛化性。
■ 所有的3个预训练任务均对PalmTree在Gemini中的最终表现所有贡献。然而,PalmTree-M和PalmTree-MC并没有显著优于其他基线模型,这说明在该下游任务中,只有基于所有3个预训练任务的完整的PalmTree模型才能够产生比基线模型更好的嵌入结果。
(2) 函数类型签名推断。函数类型签名推断是一项推断函数的参数个数及参数原始类型的任务。为了评估指令嵌入在该任务中的质量,我们选择了由Chua等人提出的EKLAVYA模型。该模型基于1个多层GRU网络并使用word2vec作为指令嵌入的方法。依据原论文,word2vec是在整个训练集上预训练得到的。然后,论文作者使用了1个GRU网络来推断函数类型签名。
在此项评估中,我们使用EKLAVYA作为下游任务来评估不同类型的嵌入的性能,如图6所示。
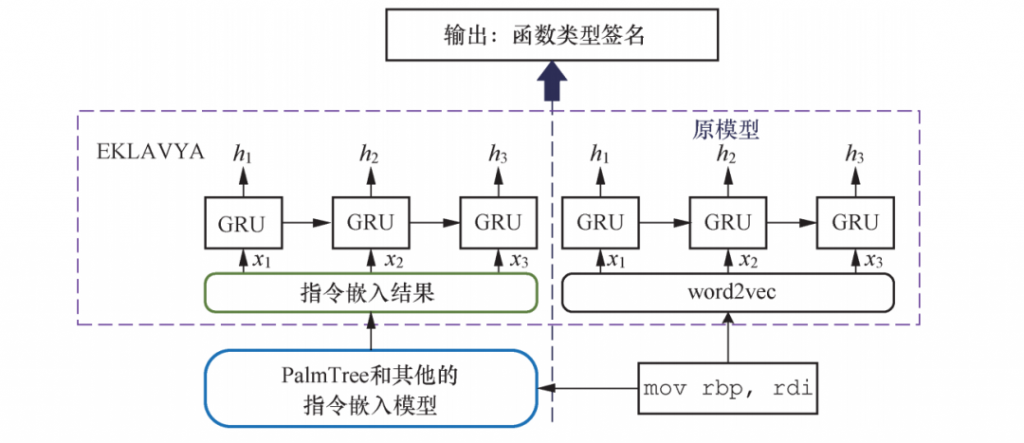
图6
我们将原EKLAVYA模型中的word2vec分别替换为独热编码、Instruction2Vec、Asm2Vec、PalmTree-M、PalmTree-MC和PalmTree。类似地,为评估下游模型的可泛化性,我们使用了完全不同的训练集和测试集(分别和Gemini实验中使用的训练集和测试集相同)。EKLAVYA实验的准确率和标准差结果如表3所示。
表3
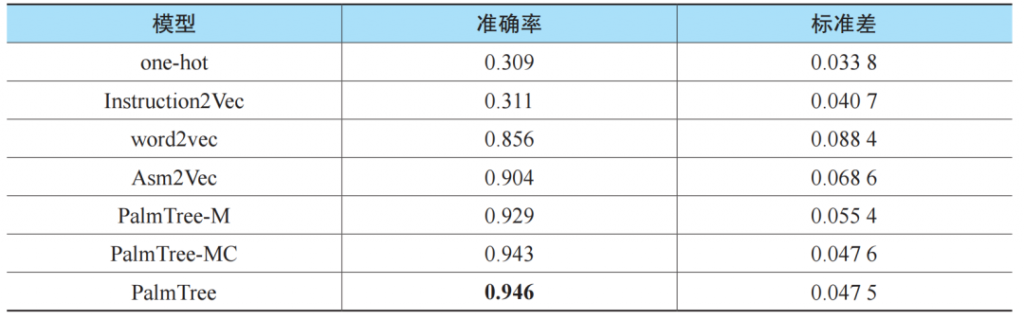
从表3我们有如下观察。
■ PalmTree和Asm2Vec能够实现比原EKLAVYA模型中word2vec更高的准确率。PalmTree在测试集上具有最好的准确率,说明了当EKLAVYA使用PalmTree作为指令嵌入模块时具有最好的可泛化性。此外,CWP(和PalmTree-MC相对应)对模型的提升具有更多的贡献,这说明了控制流信息在EKLAVYA中起到了更重要的作用。
■ 在此项评估中Instruction2Vec表现得很差,说明了如果不能恰当进行设计,人工特征构造将会对下游模型产生负面影响。
■ 独热编码的结果较差表明,一个好的指令嵌入模型的确是非常必要的。至少在此项任务中,很难仅依靠深度神经网络通过端到端训练学习到指令语义。
(3) 值集分析。DeepVSA使用一个层次化的LSTM网络进行粗粒度的值集分析,即将内存访问分为全局、堆、栈和其他区域。其将指令的原始字节流作为输入送入一个多层LSTM网络来生成指令嵌入,然后再将所生成的指令表征送入另一个多层双向LSTM网络中,希望通过该网络提取指令之间的依赖关系,并最终预测内存访问区域。
在我们的实验中,我们使用不同的指令嵌入来替换DeepVSA中已有的指令嵌入生成模型。我们使用了DeepVSA原有的测试和训练数据集,并比较不同嵌入的预测精度。由于原有的数据集仅包含原始字节,因此我们首先对这些字节进行了反汇编。我们在LSTM网络之前增加了一个嵌入层以进一步调整指令嵌入,如图7所示。
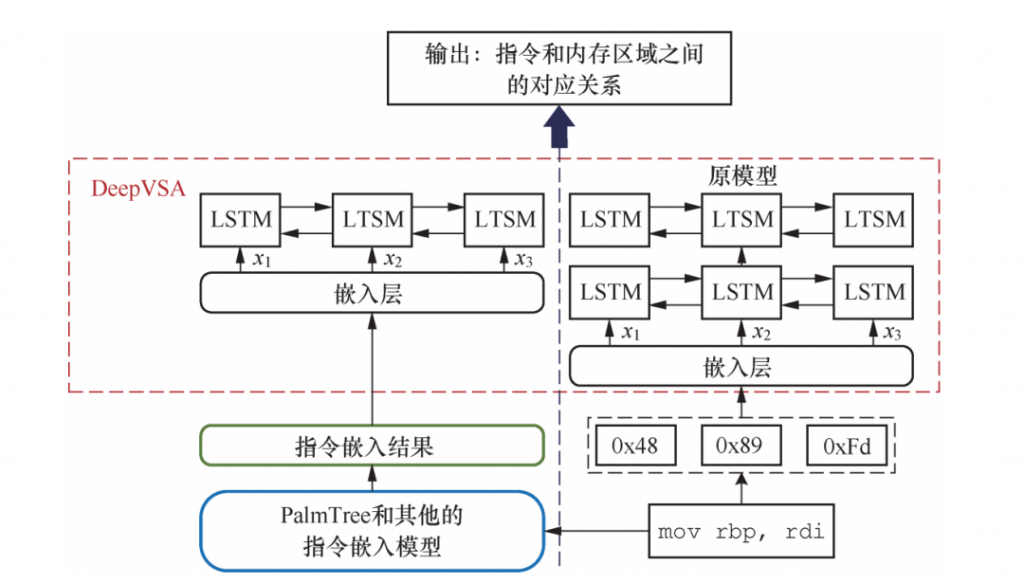
图7
表4列出了DeepVSA的实验结果。我们使用准确率(P)、召回率(R)和F1值来度量模型的表现。
表4
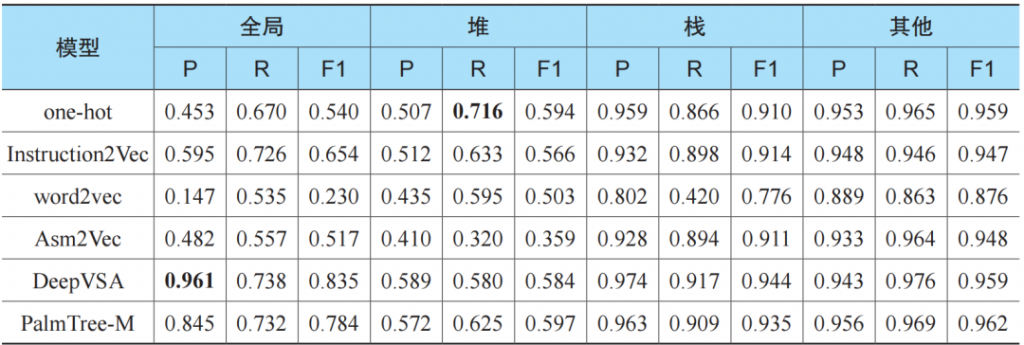
图8展示了DeepVSA在训练过程中的损失函数变化情况。
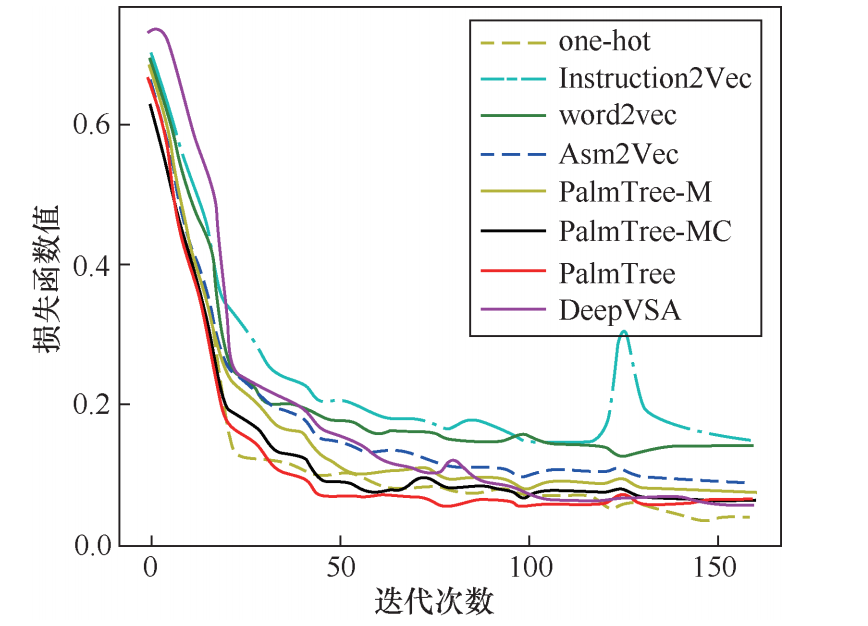
图8
基于以上结果,我们有如下的观察。
■ 在全局和堆区域预测中,PalmTree显著优于原DeepVSA及其他的基线方法。在栈和其他区域的预测中略优于其他的方法。
■ PalmTree的3个预训练任务确实都对最终结果产生了贡献,这说明PalmTree的确捕捉到了指令之间的数据流信息。相比之下,其他的指令嵌入模型并不能很好地捕捉定义使用信息。
■ 和原DeepVSA相比,PalmTree的收敛速度更快(如图8所示),这说明指令嵌入模型的确能够加速下游任务的训练过程。
结论:在所有的外部评估中,PalmTree均显著优于其他的指令嵌入模型;通过提供高质量的指令嵌入,PalmTree能够提升下游模型的训练速度和表现;相比之下,word2vec和Instruction2Vec在所有的3个下游任务中的表现均较差,说明质量较差的指令嵌入反而会损害下游模型的整体表现。
五、总结
在本文中,我们总结了在指令表征学习方面尚未解决的问题和面对的挑战。为解决存在的问题,并描述汇编语言指令的本质特点,我们提出了一个预训练的汇编语言模型并称之为PalmTree。
PalmTree可以通过自监督的训练任务在大规模、无标注的二进制语料库上进行预训练。PalmTree基于BERT模型,但使用了新设计的、能够捕捉汇编语言内在特点的预训练任务。具体而言,我们提出使用3个预训练任务来训练PalmTree:MLM、CWP和DUP。我们设计了一系列的内部和外部评估,以系统性地评价PalmTree和其他指令嵌入模型。实验结果表明,和已有模型相比,PalmTree在内部评估中有最好的表现。而在使用多个下游任务的外部评估中,PalmTree显著优于其他基线模型,并且能够显著提升下游应用的效果。因此可以得出结论:PalmTree能够产生高质量的指令嵌入,其生成的指令嵌入对不同下游二进制代码分析任务均有提升作用。
作者简介
屈宇,加州大学河滨分校尹恒教授组博士后。他的研究方向为软件安全、机器学习及深度学习理论在软件工程中的应用。屈宇博士在ACM CCS、ICSE、ASE、TSE等国际知名网络安全及软件工程会议及期刊上发表论文近30篇,参与多项国家自然科学基金及美国国家科学基金项目。作为主要完成人,他曾获2017年国家科技进步二等奖、2016年教育部科技进步一等奖。
(未完待续……)
版权声明:本研究报告由网络安全研究国际学术论坛(InForSec)汇编,人民邮电出版社出版,版权属于双方共有,并受法律保护。转载、摘编或利用其它方式使用本研究报告文字或者观点的,应注明来源。




